近日,工作中用到了sync.Pool,所谓知己知彼,百战百胜,让我们了解它,掌握它,再去运用它吧!
代码源于 go1.18.7
代码
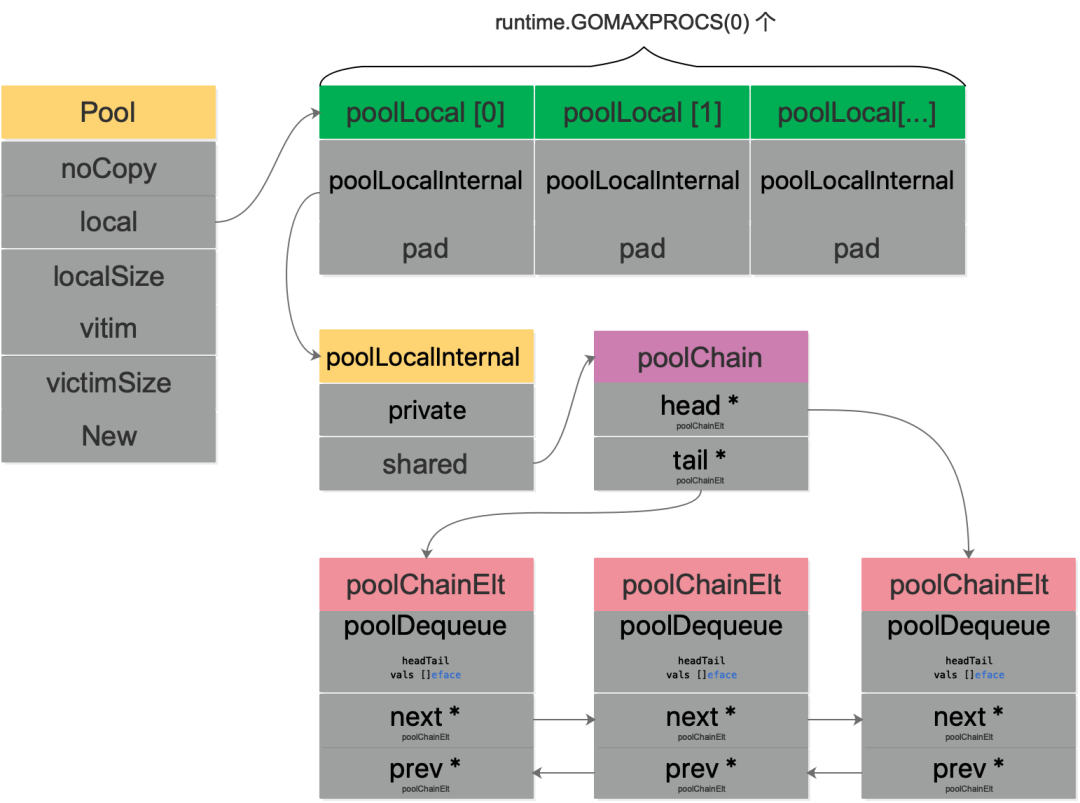
主要结构体
pool.go 中结构体
首先是pool.go文件里的一些结构体,也就是最外层的Pool
// Pool 是一组可以单独保存和检索的临时对象。
// 任何存在 Pool 中的对象都会在没有任何通知的情况下被自动的移除,所以如果 Pool 中是这个对象的唯一引用时,这个对象所使用的内存会被释放
// Pool 是并发安全的,支持多个goroutine同时使用
// Pool 旨在缓存分配了内存但是无用的对象,便于后续的重复利用,减轻GC的压力。因此,Pool 适用于简单的实现一个高效的、线程安全的空闲列表,但是它并不适合所有的空闲列表。
// Pool 的一个适当用法是管理一组临时项,这些项在包的并发独立的客户端之间静默地进行共享,被这些客户端重用。 Pool 提供了一种在许多客户端之间共同使用分配出来内存的方法。
// Pool 的一个很好的使用例子就是fmt包,它包含一个容量动态变化的临时打印缓冲区的存储空间。这个存储空间在负载变高时(比如多个goroutine同时打印时)扩张,在负载变低时缩小
// 另一方面,用 Pool 作为短期使用对象的空闲列表并不适合,因为在这种情况下,并不能很好地分摊资源开销。单独实现一个这些短期使用对象的空闲列表会更有效率。
// 首次使用后,不能复制 Pool
type Pool struct {
noCopy noCopy
// 固定大小的每个 P 的 Pool,实际类型是 [P]poolLocal
local unsafe.Pointer
// size of the local array
localSize uintptr
// 上一个周期的 local
victim unsafe.Pointer
// size of victims array
victimSize uintptr
// 随意地声明了一个当调用 Get 方法将会返回nil时的初始化方法。
// 在调用 Get 方法的同时无法修改 New 方法。此方法在初始化Pool时需要重写。
New func() any
}
// Local per-P Pool appendix.
type poolLocalInternal struct {
// P 的私有缓存区,使用时无需要加锁
private any
// 公共缓存区。本地 P 可以 pushHead/popHead;其他 P 则只能 popTail
shared poolChain
}
type poolLocal struct {
poolLocalInternal
// 将 poolLocal 补齐至两个缓存行的倍数,防止 false sharing,
// 每个缓存行具有 64 bytes,即 512 bit
// 目前我们的处理器一般拥有 32 * 1024 / 64 = 512 条缓存行
// 伪共享,仅占位用,防止在 cache line 上分配多个 poolLocalInternal
pad [128 - unsafe.Sizeof(poolLocalInternal{})%128]byte
}
从这些代码里可以看到
- 为了保证并发安全,使用了noCopy结构体,原理不再赘述,很多包中都有用到。
- 因为是
1.18.7版本的代码,所以能够看到一些泛型的新代码了,不过这些并不是我们要研究的重点。 - local 和 victim 是两个很引人注意的变量。victim 名字应该是取自于 victim cache(受害者缓存),源自于集成电路时代的一种硬件设计,后来因为技术革新没有大规模使用。刚开始看不太理解具体做什么的话可以先放一放往下继续看,看到Get方法的具体实现时,结合下面的解释,自然就明白到底victim是做什么的了。
所谓受害者缓存(Victim Cache),是一个与直接匹配或低相联缓存并用的、容量很小的全相联缓存。当一个数据块被逐出缓存时,并不直接丢弃,而是暂先进入受害者缓存。如果受害者缓存已满,就替换掉其中一项。当进行缓存标签匹配时,在与索引指向标签匹配的同时,并行查看受害者缓存,如果在受害者缓存发现匹配,就将其此数据块与缓存中的不匹配数据块做交换,同时返回给处理器。 -- 维基百科
- private 和 share的设计,在很多地方都能看到类似的设计(例如GMP模型),主要是在少量快速取用和大量缓慢取用之间做的一个权衡
- poolLocal 中 pad,其实也较为常见,了解MESI(缓存一致性协议)的话,就能理解到,如果需要并发读写的两个变量在一个缓存行中,将会造成多么麻烦的后果,而pad就是为了防止这种机制触发,用空间换时间,提高效率
poolqueue.go 中结构体
下面再来看poolqueue.go中的结构体
// poolChain 是poolDequeue的动态大小版本的实现。
// poolChain 被实现为poolDequeues的双向链表队列,每一个链表的长度都是前一个的两倍(有上限),一个链表被填满时,就会开新的链表。而取值只会在最后的链表中取,一旦最后的链表被拿空,则此链表将会被移除。
type poolChain struct {
// 头指针用于放入,只会被生产者放入,是并发安全的
head *poolChainElt
// 尾指针是用来取用和释放的,会由消费者来操作,需要保证操作是原子的
tail *poolChainElt
}
type poolChainElt struct {
poolDequeue
// next 和 prev 用于连接poolChain中相邻的 poolChainElts
// next 是用于生产者写入新的值,所以只会从初始的nil 到 写入下一个poolDequeue的非nil
// prev 是用于消费者读取值取用的,所以只会从初始被写入时的上一个poolDequeue的非nil变为没有了上一个poolDequeue的nil
next, prev *poolChainElt
}
// poolDequeue是一个无锁化编程实现的非固定大小的单生产者、多消费者的队列。单个生产者可以从头部放入和取用,消费者只可以从尾部取用。
//它还有一个额外的功能,就是清除未使用的插槽位,以避免不必要的对象长时间保留。这对于sync.Pool很重要,但通常不是文献中考虑的属性(这里没太明白)。
type poolDequeue struct {
// headTail 由head和tail两个32位的指针打包组成,它们都是poolDequeue的下标。
// tail 含义是队列中最老的数据
// head 含义是下一个将要被填充的位置
// [tail, head)位置内的插槽是被消费者拥有使用的。直到所有的插槽都被清空时,消费者将会去上一个队列中操作、使用,也就意味着,此时,此队列的所有权会被移交给生产者。
// head指针在最高有效位上,以便我们可以原子的添加值到其中,并且溢出无害
headTail uint64
// vals 是存 any 的环形缓存区,其大小必须是2的幂
// 如果槽为空,则vals[i].typ为零,否则就为非零。一个槽仍在使用,直到尾部索引移过它并且typ设置为零。这由消费者原子地设置为零,由生产者原子地读取。
vals []eface
}
- 看描述,poolDequeue像是最初版本的pool的share字段的实现,但是poolDequeue有明显的缺点,就是长度固定,每个poolDequeue就是一个固定的环形缓存区(指针),长度由常量决定
const dequeueBits = 32
// dequeueLimit 最多为(1<<dequeueBits)/2,因为检测填充度取决于环绕环形缓冲区而不环绕索引。我们除以4, 以适合32位整数。
const dequeueLimit = (1 << dequeueBits) / 4
- 在此版本实现中,poolDequeue之外,还套了一层poolChain,这样就可以解除长度的限制,增加容量,也正因此,需要增加一套创建新poolDequeue和释放空poolDequeue等管理操作
存储结构图
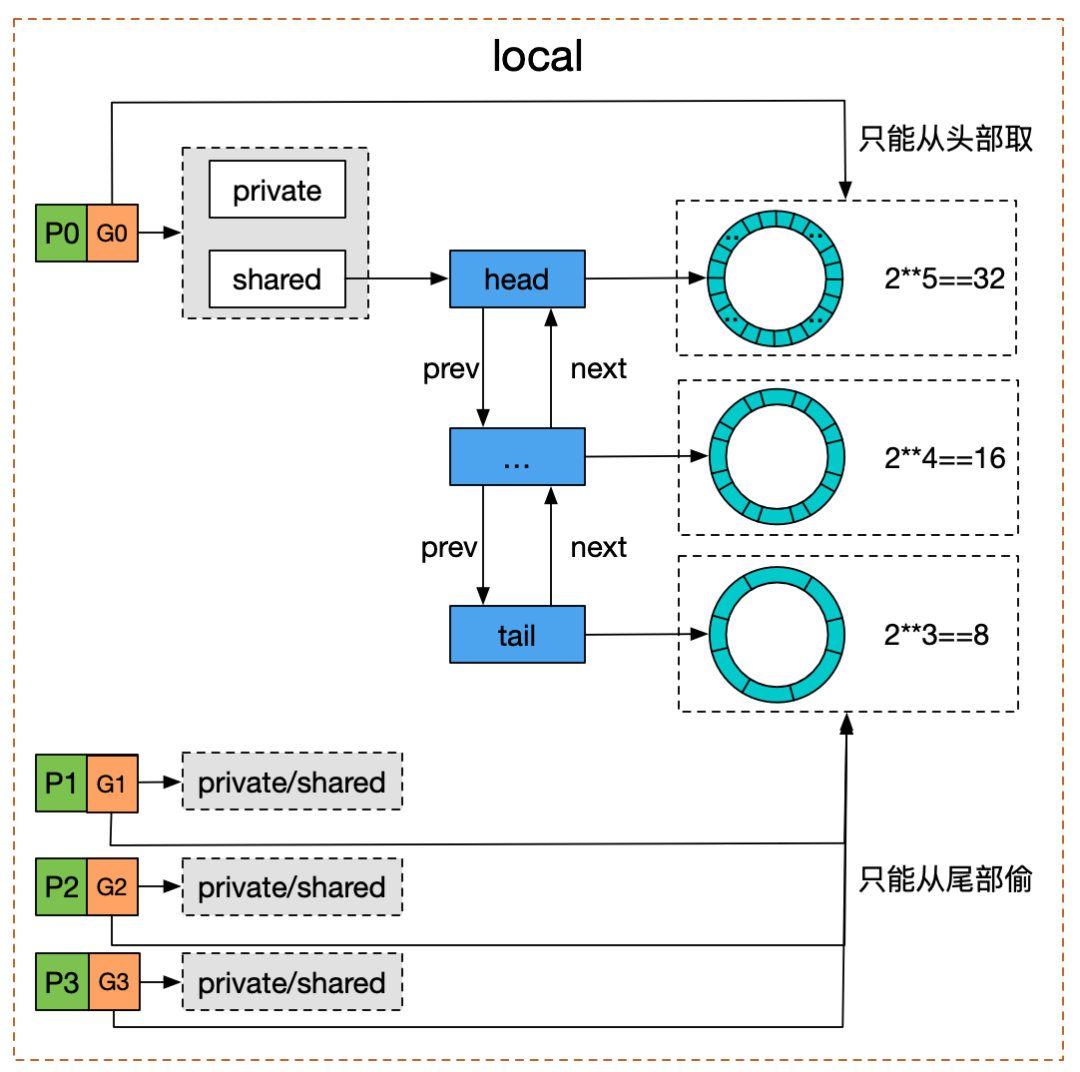
首先是会有一个最热的本地private区域,其次设立本地P和外部P两大块的share,这样的组织方式可以有层次的区分内存的速度和容量的平衡
图片来自深度解密Go语言之sync.pool
Get方法
具体操作的代码,主要在注释中说明作用和记录体会。首先记住这张图,对我们理解代码细节很有帮助
图片来自请问sync.Pool有什么缺点?
func (p *Pool) Get() any {
// pin的逻辑后续再说,统一解释。锁定GMP的P,防止Goroutine切换和阻止gc
l, pid := p.pin()
// 优先取用private
x := l.private
l.private = nil
if x == nil {
// 尝试从shared队列中拿取
x, _ = l.shared.popHead()
if x == nil {
// shared队列中也没有,再从victim中拿取,上次GC遗留下来的“老”数据
x = p.getSlow(pid)
}
}
runtime_procUnpin()
// 实在获取不到,调用New函数生成新的值
if x == nil && p.New != nil {
x = p.New()
}
return x
}
// Get() 中 shared.popHead() 调用的是poolChain 的 popHead()
func (c *poolChain) popHead() (any, bool) {
d := c.head
for d != nil {
// 从poolDequeue的头部拿取一个,没有也无需移动指针,机制保证头部中是最有可能存在值的
if val, ok := d.popHead(); ok {
return val, ok
}
// 继续往上一个poolDequeue中寻找,直到本身是第一个节点,没有上一个节点后,返回nil退出
d = loadPoolChainElt(&d.prev)
}
return nil, false
}
// poolChain 的 popHead() 中的 popHead() 调用的是 poolDequeue 的 popHead()
func (d *poolDequeue) popHead() (any, bool) {
var slot *eface
for {
ptrs := atomic.LoadUint64(&d.headTail)
// 分离头尾指针
head, tail := d.unpack(ptrs)
// 存满后并不会让头尾指针重叠,所以相等只会意味着环形缓冲区为空
if tail == head {
return nil, false
}
// 这里是获取本地share的值,会从头部获取值
head--
ptrs2 := d.pack(head, tail)
// 无锁化编程思维,使用‘乐观锁’方式,取得slot
if atomic.CompareAndSwapUint64(&d.headTail, ptrs, ptrs2) {
slot = &d.vals[head&uint32(len(d.vals)-1)]
break
}
}
val := *(*any)(unsafe.Pointer(slot))
if val == dequeueNil(nil) {
val = nil
}
// 清空slot,这里直接使用赋空值的方式,在读取和写入的机制中,head位置只会有本地share读取时用到,而写入和其他P的share读取时都会是在tail位置操作
*slot = eface{}
return val, true
}
上面的操作都是从本地private中获取值,均找不到时候,需要从其他的share中偷取,或者从victim中取
func (p *Pool) getSlow(pid int) any {
// See the comment in pin regarding ordering of the loads.
size := runtime_LoadAcquintptr(&p.localSize) // load-acquire
locals := p.local // load-consume
// 根据P的个数,从下一个P的local处开始,一个个从其他P的share尾部偷
for i := 0; i < int(size); i++ {
l := indexLocal(locals, (pid+i+1)%int(size))
if x, _ := l.shared.popTail(); x != nil {
return x
}
}
// 开始尝试读取victim中的数据,与上面不同的是,本次不是从`indexLocal(locals, (pid+i+1)%int(size))`的尾部偷,而是从`indexLocal(locals, (pid+i)%int(size))`的尾部开始偷取,这么做,是为了想让其中的值尽可能老化(放入和取值方向不同,所以可以做到让值不会经常被调用)
size = atomic.LoadUintptr(&p.victimSize)
if uintptr(pid) >= size {
return nil
}
locals = p.victim
l := indexLocal(locals, pid)
if x := l.private; x != nil {
l.private = nil
return x
}
for i := 0; i < int(size); i++ {
l := indexLocal(locals, (pid+i)%int(size))
if x, _ := l.shared.popTail(); x != nil {
return x
}
}
// 到这里还没有返回,就是说明取不到值,也就是victim为空了,那就置victimSize为0,就不会再从这里去取值了
atomic.StoreUintptr(&p.victimSize, 0)
return nil
}
// getSlow() 中的 share.popTail() 为 poolChain的 popTail()
func (c *poolChain) popTail() (any, bool) {
d := loadPoolChainElt(&c.tail)
if d == nil {
return nil, false
}
for {
// popHead中是顺着prev的方向遍历,next其实就是反向遍历,这里含义可能会有点迷糊
d2 := loadPoolChainElt(&d.next)
if val, ok := d.popTail(); ok {
return val, ok
}
// d2为空,那就是这个poolChain是第一个了,不用再找了
if d2 == nil {
return nil, false
}
// 无锁操作,d中无值,清空d
if atomic.CompareAndSwapPointer((*unsafe.Pointer)(unsafe.Pointer(&c.tail)), unsafe.Pointer(d), unsafe.Pointer(d2)) {
storePoolChainElt(&d2.prev, nil)
}
d = d2
}
}
// poolChain的 popTail() 中的 popTail() 为 poolChain的 popTail()
func (d *poolDequeue) popTail() (any, bool) {
var slot *eface
for {
ptrs := atomic.LoadUint64(&d.headTail)
head, tail := d.unpack(ptrs)
if tail == head {
return nil, false
}
// 与popHead中不同,这里是tail往前寻找
ptrs2 := d.pack(head, tail+1)
if atomic.CompareAndSwapUint64(&d.headTail, ptrs, ptrs2) {
slot = &d.vals[tail&uint32(len(d.vals)-1)]
break
}
}
val := *(*any)(unsafe.Pointer(slot))
if val == dequeueNil(nil) {
val = nil
}
// 与popHead中不同,这里置空了val,再原子操作置空了typ,typ会在pushHead中用到,判断typ是否为空,所以这里需要原子操作,因为在写入和读取中,tail位置是会有冲突操作的
slot.val = nil
atomic.StorePointer(&slot.typ, nil)
return val, true
}
Put方法
// Put adds x to the pool.
func (p *Pool) Put(x any) {
// fail fast
if x == nil {
return
}
// race
// 绑定p,防止goroutine切换,同时阻止了GC,GC需要将各任务切换走完成抢占后才会开始STW
l, _ := p.pin()
// 优先检查private,清理传入的参数
if l.private == nil {
l.private = x
x = nil
}
// x不为nil,private已经有值,则放入share队列中
if x != nil {
l.shared.pushHead(x)
}
// 解除p绑定
runtime_procUnpin()
// race
}
// Put() 中的shared.pushHead() 为 poolChain 的 pushHead()
func (c *poolChain) pushHead(val any) {
d := c.head
if d == nil {
// Initialize the chain.
const initSize = 8 // Must be a power of 2
d = new(poolChainElt)
d.vals = make([]eface, initSize)
c.head = d
storePoolChainElt(&c.tail, d)
}
if d.pushHead(val) {
return
}
// 上面放入失败,意味着此 poolChain 已满,需要按两倍长度建立新的节点,有限长
The current dequeue is full. Allocate a new one of twice
// the size.
newSize := len(d.vals) * 2
if newSize >= dequeueLimit {
// 限长
newSize = dequeueLimit
}
d2 := &poolChainElt{prev: d}
d2.vals = make([]eface, newSize)
c.head = d2
storePoolChainElt(&d.next, d2)
d2.pushHead(val)
}
// poolChain 的 pushHead() 中的 pushHead() 为 poolDequeue 的 pushHead()
func (d *poolDequeue) pushHead(val any) bool {
ptrs := atomic.LoadUint64(&d.headTail)
head, tail := d.unpack(ptrs)
if (tail+uint32(len(d.vals)))&(1<<dequeueBits-1) == head {
// Queue is full.
return false
}
slot := &d.vals[head&uint32(len(d.vals)-1)]
// 置空值时,type也会为nil,如果值的typ不为nil, 则说明当前head中有值,因为刚才有判断进来时候的状态,所以可能有其他goroutine在操作
typ := atomic.LoadPointer(&slot.typ)
if typ != nil {
// Another goroutine is still cleaning up the tail, so
// the queue is actually still full.
return false
}
// The head slot is free, so we own it.
if val == nil {
val = dequeueNil(nil)
}
*(*any)(unsafe.Pointer(slot)) = val
// 还记得拿取时候,拿走之后的操作是head--吗?现在push的话,需要把head++这里只是换了种方式
atomic.AddUint64(&d.headTail, 1<<dequeueBits)
return true
}
Pin方法
我们先来看下pool中pin的代码,然后逐步探索下,为什么pin之后P不会被抢占
pool.go
// pin函数会把g绑定到当前的P上,防止被抢占
func (p *Pool) pin() (*poolLocal, int) {
pid := runtime_procPin()
// In pinSlow we store to local and then to localSize, here we load in opposite order.
// Since we've disabled preemption, GC cannot happen in between.
// Thus here we must observe local at least as large localSize.
// We can observe a newer/larger local, it is fine (we must observe its zero-initialized-ness).
s := runtime_LoadAcquintptr(&p.localSize) // load-acquire
l := p.local // load-consume
if uintptr(pid) < s {
return indexLocal(l, pid), pid
}
return p.pinSlow()
}
func (p *Pool) pinSlow() (*poolLocal, int) {
// Retry under the mutex.
// Can not lock the mutex while pinned.
runtime_procUnpin()
allPoolsMu.Lock()
defer allPoolsMu.Unlock()
pid := runtime_procPin()
// poolCleanup won't be called while we are pinned.
s := p.localSize
l := p.local
if uintptr(pid) < s {
return indexLocal(l, pid), pid
}
if p.local == nil {
allPools = append(allPools, p)
}
// If GOMAXPROCS changes between GCs, we re-allocate the array and lose the old one.
size := runtime.GOMAXPROCS(0)
local := make([]poolLocal, size)
atomic.StorePointer(&p.local, unsafe.Pointer(&local[0])) // store-release
runtime_StoreReluintptr(&p.localSize, uintptr(size)) // store-release
return &local[pid], pid
}
runtime中pin的代码如下
src/runtime/proc.go
// 可以看到,他是在对应m上,将locks字段加1
func procPin() int {
_g_ := getg()
mp := _g_.m
mp.locks++
return int(mp.p.ptr().id)
}
// 那为什么这样就可以完成防止抢占了呢,来看下抢占的代码
func preemptone(_p_ *p) bool {
mp := _p_.m.ptr()
if mp == nil || mp == getg().m {
return false
}
gp := mp.curg
if gp == nil || gp == mp.g0 {
return false
}
gp.preempt = true
// Every call in a goroutine checks for stack overflow by
// comparing the current stack pointer to gp->stackguard0.
// Setting gp->stackguard0 to StackPreempt folds
// preemption into the normal stack overflow check.
gp.stackguard0 = stackPreempt
// Request an async preemption of this P.
if preemptMSupported && debug.asyncpreemptoff == 0 {
_p_.preempt = true
preemptM(mp)
}
return true
}
可以看到,主要的操作就是这两条,并没有做什么实质的操作
gp.preempt = true
gp.stackguard0 = stackPreempt
看注释,如此设置之后就可以让goroutine做栈溢出检测时发现有溢出,进而进行栈扩容,在扩容时进行调度
src/runtime/preempt.go
而扩容时的判断函数如下,可以看到,其中就有判断 M 的 locks字段,这样一来,就串起来了。pin时置了 M 中locks字段,阻止了 P 被抢占,也正因为如此,需要抢占所有 P 的 GC 过程自然也无法完成了。
func canPreemptM(mp *m) bool {
return mp.locks == 0 && mp.mallocing == 0 && mp.preemptoff == "" && mp.p.ptr().status == _Prunning
}
poolCleanup方法
先看pool.go中的代码,这里会做一个注册操作,将pool的清理函数注册到GC流程里,在STW阶段调用。清理函数会清理掉victim中的内容,然后将现有local中的内容赋值到victim中,降低GC压力,并逐步的将值移到local中(从victim取用后会放入local中),提高利用率。
pool.go
func poolCleanup() {
// This function is called with the world stopped, at the beginning of a garbage collection.
// It must not allocate and probably should not call any runtime functions.
// Because the world is stopped, no pool user can be in a
// pinned section (in effect, this has all Ps pinned).
// Drop victim caches from all pools.
for _, p := range oldPools {
p.victim = nil
p.victimSize = 0
}
// Move primary cache to victim cache.
// 之前老版本中,这里会直接将local清空,这样会增加GC压力,也必然会有更多的miss 和 New()
for _, p := range allPools {
p.victim = p.local
p.victimSize = p.localSize
p.local = nil
p.localSize = 0
}
// The pools with non-empty primary caches now have non-empty
// victim caches and no pools have primary caches.
oldPools, allPools = allPools, nil
}
func init() {
runtime_registerPoolCleanup(poolCleanup)
}
runtime/mgc.go
func sync_runtime_registerPoolCleanup(f func()) {
poolcleanup = f
}
func clearpools() {
// clear sync.Pools
if poolcleanup != nil {
poolcleanup()
}
// ...无关省略
}
// ...无关省略
func gcStart(trigger gcTrigger) {
mp := acquirem()
if gp := getg(); gp == mp.g0 || mp.locks > 1 || mp.preemptoff != "" {
releasem(mp)
return
}
releasem(mp)
// ...无关省略
gcBgMarkStartWorkers()
gcResetMarkState()
// ...无关省略
systemstack(stopTheWorldWithSema)
systemstack(func() {
finishsweep_m()
})
// clearpools before we start the GC. If we wait they memory will not be
// reclaimed until the next GC cycle.
// 清理pool内存
clearpools()
// ...无关省略
}
Go 1.13中 sync.Pool 是如何优化的?
- victim机制引入,防止缓存数量过多时,增加STW阶段工作量,同时也防止每次清理后命中率下降,过多调用New函数,增加额外消耗
- 去掉代码中的锁,实现无锁化编程,提高并发效率,也减少了抢锁多次失败的资源消耗等问题
感悟
- victim 是非常值得学习的一个应用,一举多得,其根本操作还是老生常谈的空间换时间,但是这种触类旁通的点睛之笔,真的是令人拍案叫绝
- 无锁化编程是一种思维,在日益凸显的高并发生产环境下,这个思维越来越适用和优秀,也越发对我们提高了要求,努力吧!