文章起于一次死锁案例
问题引发思考,思考带动学习
切身的面对让我了解了更多关于事务和锁的内容
本文内容基于MySQL 5.7版本官方文档。只讨论InnoDB引擎。
事务并发下存在的问题
首先我们来看下事务并发下可能存在的几类问题。设定级别的目的也正是为了在解决问题的同时保证最大的并发性能,不然为啥要费这个劲儿呢,直接串行化莽就是了。
具体示例可以找下示例文章,这里只给出简单的定义
脏读(dirty read)
读取了另一个事务未提交的修改
不可重复读(unrepeatable read)
读取了另一个事务提交之后的修改
幻读(phantom read)
同样的条件,两次读取得到的结果集不一样,跟不可重复度不一样的是,幻读主要面临的是其他事务的insert或者delete,而不是update
丢失更新(lost update)
上面的三种问题主要是读、写两个事务间的问题,丢失更新是写、写两个事务间的问题。
丢失更新主要分为两类,回滚覆盖(第一类丢失更新),提交覆盖(第二类丢失更新)。
即,被其他事务的回滚或者提交影响了本事务的修改。但一般来说,回滚操作不应该影响其他正常提交的事务,毕竟回滚要做的只是回滚本事务的影响,所以基本上不会出现回滚覆盖问题。
带着问题,我们去看下各个隔离级别,都解决了哪些问题
事务级别
顺序基于英文官方文档
可重复读(REPEATABLE READ)
这个是InnoDB的默认隔离级别,在同一个事务里,同样条件下的查询都会是稳定一致的。
对于会产生加锁行为的读取(例如select for update 或者 select lock in share mode)、更新、删除等操作,会根据查询的条件区分,加不同的锁:
- 当查询条件是一个唯一条目的查询条件并且命中唯一索引时,只会加行锁,不会加间隙锁
- 其他查询条件时,为了防止幻读,会添加间隙锁 或者 next-key锁
至于,RR是否可以解决幻读问题,大家可以看看这篇讨论:
Innodb 中 RR 隔离级别能否防止幻读?
个人观点倾向于,RR并没有完全解决幻读。
MySQL 用于实现事务隔离级别 MVCC 机制中衍生出了「当前读」和「快照读」两个概念。InnoDB在可重复读级别下的「当前读」通过Next-Key Lock锁机制解决了幻读问题,但是在「快照读」时还是会存在幻读,详细可以看下上面的链接
已提交读(READ COMMITTED)
在这种隔离级别下,连续的查询中,甚至哪怕是在同一个事务中,也会读取到新的已经提交的记录。
已提交读中,对于会产生加锁行为的读取(例如select for update 或者 select lock in share mode)、更新、删除等操作,只会加行锁,而只有外键和唯一键的检查才会添加间隙锁。
因为没有了间隙锁,所以会出现幻读的情况,也就是允许在查询中的间隙里添加新行。关于幻读
已提交读仅支持基于行的二进制日志记录。如果使用已提交读这个隔离级别,并且有binlog_format=MIXED 这条配置的话,那服务会使用基于行的二进制日志。
使用已提交读还有会如下额外的影响:
- 对于更新和删除操作,InnoDB只会对受影响的行加行锁,对于没有匹配到的行的锁,在where条件处理完之后就会释放掉,这样大大降低了死锁的概率,但是并不会完全避免。
- 对于更新的情况,如果一行已经被锁定了,InnoDB会执行“半一致性”(
semi-consistent)读,这时会返回最新的提交结果,从而判断是否需要更新,如果有行命中(需要更新),MySQL会再次读取一次,并加锁或者等待加锁。 - 已提交读的影响与配置变量
innodb_locks_unsafe_for_binlog类似,但是有一些区别
(1)innodb_locks_unsafe_for_binlog只能全局设定,而隔离级别可以全局可以局部
(2)innodb_locks_unsafe_for_binlog只能启动时设定,而隔离级别可以动态更改
关于已提交读的影响,官方文档有一个很不错的示例,可以自己通读下
这里只摘一些简单对比
前提:
CREATE TABLE t (a INT NOT NULL, b INT) ENGINE = InnoDB;
INSERT INTO t VALUES (1,2),(2,3),(3,2),(4,3),(5,2);
COMMIT;
当执行如下语句时
START TRANSACTION;
UPDATE t SET b = 5 WHERE b = 3;
可重复读加锁表现:
x-lock(1,2); retain x-lock
x-lock(2,3); update(2,3) to (2,5); retain x-lock
x-lock(3,2); retain x-lock
x-lock(4,3); update(4,3) to (4,5); retain x-lock
x-lock(5,2); retain x-lock
已提交读加锁表现:
x-lock(1,2); unlock(1,2)
x-lock(2,3); update(2,3) to (2,5); retain x-lock
x-lock(3,2); unlock(3,2)
x-lock(4,3); update(4,3) to (4,5); retain x-lock
x-lock(5,2); unlock(5,2)
未提交读(READ UNCOMMITTED)
未提交读中,查询语句不会产生锁,也因此会查询到其他事务产生的改变,也就是会产生脏读。其他语句时,表现和已提交读表现一致。
可串行化(SERIALIZABLE)
此级别类似于可重复读,但是当禁用自动提交时,InnoDB 会将所有普通查询语句隐式转换为select lock in share mode;如果启用了自动提交,则每条查询语句都是单独的一个事务。因此它是只读的,并且如果作为一致(非锁定)读取执行并且不需要阻塞其他事务时可以序列化。(如果在其他事务修改了选定的行的情况下要强制一个普通的查询阻塞,则需要禁用自动提交。)
隔离级别小结
-
四个隔离级别分别是为了除了不同的问题
由低到高依次为未提交读、已提交读、可重复读、可串行化,这四个级别可以逐个解决脏读 、不可重复读 、幻读 这几类问题。InnoDB默认情况下是可重复读,已经可以解决脏读、幻读以及绝大部分的幻读。
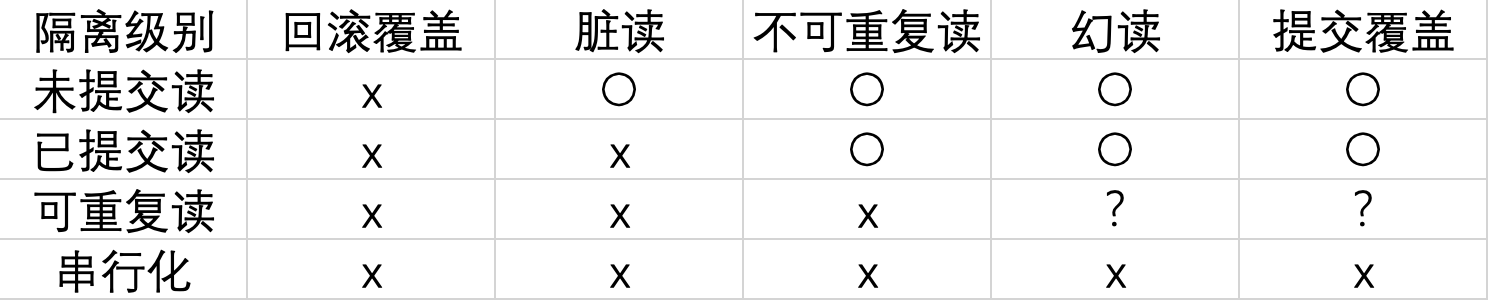
而对于丢失更新问题,正如我们上面所说的,回滚覆盖基本不会出现。而提交覆盖理论上因为读写锁的存在,在可重复读级别就不会出现,但是和幻读的情况类似,也是因为「快照读」的存在,导致了可重复读级别中并没有完全的解决这个问题。 -
隔离级别的实现并非只能是加锁
传统的隔离级别是基于锁实现的,这种方式叫做 基于锁的并发控制(Lock-Based Concurrent Control,简写 LBCC)。除了锁,实现并发问题的方式还有时间戳,多版本控制等等,这些也可以称为无锁的并发控制
锁类别
说完了事务隔离级别,下面我们再来看下InnoDB中锁的类别,然后分析下每种锁的作用和加锁情况。
共享锁和排他锁(Shared and Exclusive Locks)
InnoDB 实现了标准的行级锁,其中包括共享(s)锁和排他(x)锁两种。
- 共享(S)锁允许持有锁的事务读取行。
- 排他(X)锁允许持有锁的事务更新或删除行。
事务持有S锁时,允许其他事务持有S锁,但不允许其他事务持有X锁。只有当所有S锁释放后,才能获取X锁,而获取X锁后,会阻塞其他事务申请S锁或者X锁。
意向锁(Intention Locks)
意向锁是表级锁,指示事务稍后对表中的某一行需要哪种类型的锁(共享锁或排他锁)
- 意向共享锁(IS)指事务打算对表中单个行添加共享锁
- 意向排他锁(IX)指事务打算对表中单个行添加排他锁
意向锁协议如下:
- 事务在获得表中某一行的S锁之前,必须首先获得表上的IS锁或IX锁。
- 事务在获得表中某一行的X锁之前,必须首先获得表上的IX锁。
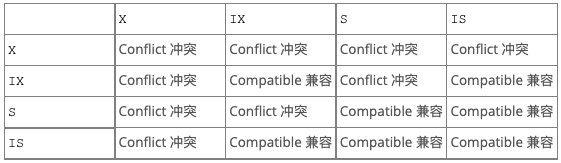
这张图相信大家都不陌生,这里可以作为参考备查。
(1)意向锁并不会直接阻塞什么,只是表明当前表中加锁状态和加锁意向状态。
(2)如果请求事务与现有锁兼容,则可以拿到锁,但如果与现有锁冲突,则无法拿到锁。事务会一直等待,直到产生冲突的现有锁被释放。如果锁请求与现有锁冲突,并且会导致死锁,则会产生报错
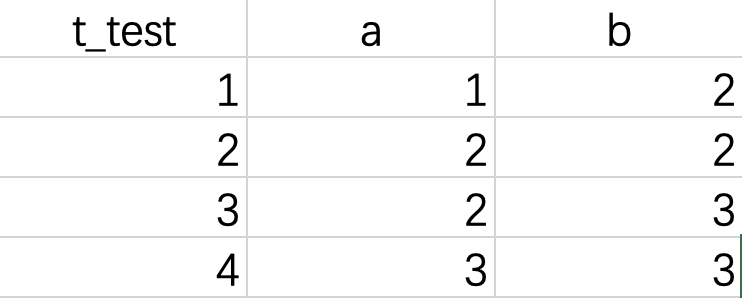
记录锁(Record Locks)
记录锁没有太多要说的,最主要的就是它是锁定在索引记录上的,这并不代表着它只锁索引,而是会顺着索引去锁定对应的所有主键记录。
例如,锁定索引b上的b=2,下表中,第一和第二行都会被锁定
间隙锁(Gap Locks)
间隙锁是在两个索引记录之间或者单个索引构成的区间只上添加的锁,无论某些区间内的值是否存在,都会被禁止更改。
查询条件命中唯一索引(包括主键)查询唯一行的语句不需要间隙锁定。如果查询条件没有索引或者命中非唯一索引,将会锁定条件前面的空白。
冲突的X锁和S锁,可能由不同的事务在一个间隙上持有(在记录行上不允许)。例如,事务A可以对间隙持有共享间隙锁(gap S-lock),而事务B对同一间隙持有排他间隙锁(gap X-lock)。允许使用冲突的间隙锁的原因是,如果从索引中清除了一个记录,则必须合并不同事务在记录上持有的间隙锁。
InnoDB 中的间隙锁是“单纯抑制性的”(purely inhibitive),间隙锁唯一目的是防止其他事务插入到这个间隙中。所以间隙锁可以共存。共享间隙锁和排他间隙锁之间没有区别。它们之间在间隙锁的功能上没有冲突且功能相同。
可以显式的禁用间隙锁。比如将事务隔离级别更改为已提交读 或者 启用innodb_locks_unsafe_for_binlog变量(不推荐)。在这种情况下,读操作不会产生间隙锁,外键约束检查和唯一键检查时依然会用到。
临键锁(Next-Key Locks)
临键锁是记录锁和索引记录前的间隙锁的组合。
其实我不太确定这个名字是不是一个公认的,因为大部分地方看到这个锁都是直接写的英文
其实如果说间隙锁是一个开区间的话,那么临键锁就是一个闭区间,这样应该会更好理解一些。
默认情况下,InnoDB在可重复读时会加临键锁,主要目的是防止幻读
插入意向锁(Insert Intention Locks)
插入意向锁是由insert语句预先设置的一种特殊的间隙锁,代表插入的意图,所以有时候也把它简写成“II GAP”。插入意向锁彼此之间不需要等待。假设有值为4和7的索引记录。尝试插入值5和6的两个事务,每个事务在获得插入行的排他锁之前用插入意向锁锁锁定4和7之间的间隙,但是因为他们并不是插入同一行,所以并不会产生冲突,可以同时拿到排他锁(X锁)
自增锁(AUTO-INC Locks)
自增锁是一种特殊的表级锁,当向带有自增列的表中插入数据时,会产生自增锁。举一个最简单的例子,如果一个事务正在向表中插入值,那么任何其他事务都必须暂停自己的插入操作等待之前的插入完成,然后接收连续的自增值。
更多信息,戳:AUTO _ increment Handling
空间索引谓词锁(Predicate Locks for Spatial Indexes)
中文名字是谷歌翻译的,不过这种锁我也不了解,感兴趣可以去官方文档看下,这里就不班门弄斧了。
综合下来,表锁有自增锁和意向锁,行锁有记录锁、间隙锁、临键锁、插入意向锁
表锁之间往往没有讨论的必要,他们也不会直接产生阻塞,所以我们常见的,就是行锁之间的兼容矩阵:
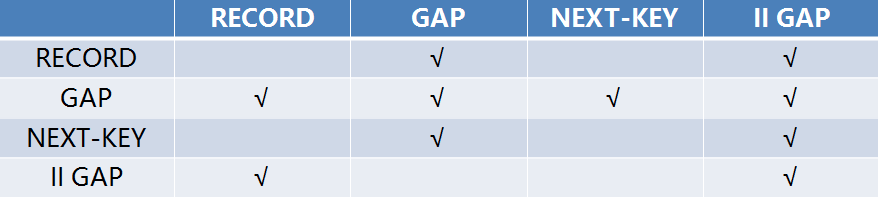
除了插入意向锁之外,其他三个其实是对称的,比较好记。
常规语句加锁分析
- 常见的 DDL 语句(如 ALTER、CREATE 等)加表级锁,且这些语句为隐式提交,不能回滚;
- SELECT ... 语句正常情况下为快照读,不加锁;可串行化隔离级别下,为当前读,加S锁。
- SELECT ... LOCK IN SHARE MODE 语句为当前读,加 S 锁;
- SELECT ... FOR UPDATE 语句为当前读,加 X 锁;
- 常见的 DML 语句(如 INSERT、DELETE、UPDATE)为当前读,加 X 锁;
以上这些行锁,在常规的可重复读级别下,又需要根据查询条件及其命中索引有所区分
(1)能定位到唯一键的具体行则为记录锁
(2)命中的是非唯一索引或者命中的是空隙那就是间隙锁
(3)如果命中了行并且还命中了一个区间,那会是一个临键锁或者间隙锁(命中的行是下边界,为临键锁,命中的行是上边界,是间隙锁)
(4)插入意向锁是插入操作独有的预先加的锁。这些遇到复杂情况会比较繁复,需要具体分析,这一块我也不是很擅长,共同进步吧。
死锁日志分析
本来是准备具体分析一个死锁案例的,但是发现,死锁情况分析网上已经有很多,这里主要说下如何分析一份死锁日志吧
开启日志&监控
首先是拿到可供分析的日志和监控。5.6之后,推荐使用系统参数,不再用更改系统表了
-- 开启标准监控
set GLOBAL innodb_status_output=ON;
-- 开启锁监控
set GLOBAL innodb_status_output_locks=ON;
-- 开启死锁日志
set GLOBAL innodb_print_all_deadlocks=ON;
阅读死锁日志
(1) TRANSACTION:
TRANSACTION 182335752, ACTIVE 0 sec inserting
ACTIVE 0 sec 表示事务活动时间
inserting 为事务当前正在运行的状态,可能的事务状态有:fetching rows,updating,deleting,inserting 等。
mysql tables in use 1, locked 1
LOCK WAIT 11 lock struct(s), heap size 1184, 2 row lock(s), undo log entries 15
tables in use 1 表示有一个表被使用
locked 1 表示有一个表锁
LOCK WAIT 表示事务正在等待锁
11 lock struct(s) 表示该事务的锁链表的长度为 11,每个链表节点代表该事务持有的一个锁结构,包括表锁,记录锁以及自增锁等
heap size 1184 为事务分配的锁堆内存大小。
2 row lock(s) 表示当前事务持有的行锁个数,通过遍历上面提到的 11 个锁结构,找出其中类型为 LOCK_REC 的记录数
undo log entries 15 表示当前事务有 15 个 undo log 记录,因为二级索引不记 undo log,说明该事务已经更新了 15 条聚集索引记录。
MySQL thread id 12032077, OS thread handle 0x7ff35ebf6700, query id 196418265 10.40.191.57 RW_bok_db update
这里是事务的线程信息,以及数据库 IP 地址和数据库名,对我们分析死锁用处不大。
INSERT INTO bok_task
1 ( order_id ...
这里显示的是正在等待锁的 SQL 语句,死锁日志里每个事务都只显示一条 SQL 语句,这对我们分析死锁很不方便,我们必须要结合应用程序去具体分析这个 SQL 之前还执行了哪些其他的 SQL 语句,或者根据 binlog 也可以大致找到一个事务执行的 SQL 语句。
(1) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 300 page no 5480 n bits 552 indexorder_id_unof tablebok_db.bok_tasktrx id 182335752 lock_mode X insert intention waiting
这里显示的是事务正在等待什么锁
RECORD LOCKS 表示记录锁(并且可以看出要加锁的索引为 order_id_un),space id 为 300,page no 为 5480,n bits 552 表示这个记录锁结构上留有 552 个 bit 位(该 page 上的记录数 + 64)。
lock_mode X 表示该记录锁为排他锁
insert intention waiting 表示要加的锁为插入意向锁,并处于锁等待状态。
在上面有提到 innodb_status_output_locks 这个系统变量可以开启 InnoDb 的锁监控,如果开启了,这个地方还会显示出锁的一些额外信息,包括索引记录的 info bits 和数据信息等:
Record lock, heap no 2 PHYSICAL RECORD: n_fields 2; compact format; info bits 0
0: len 4; hex 80000002; asc ;;
1: len 4; hex 80000001; asc ;;
四种行锁对应的死锁日志各不相同,如下:
- 记录锁(LOCK_REC_NOT_GAP): lock_mode X locks rec but not gap
- 间隙锁(LOCK_GAP): lock_mode X locks gap before rec
- Next-key 锁(LOCK_ORNIDARY): lock_mode X
- 插入意向锁(LOCK_INSERT_INTENTION): lock_mode X locks gap before rec insert intention
这里有一点要注意的是,并不是在日志里看到 lock_mode X 就认为这是临键锁,因为还有一个例外:
如果在上边界上加锁,locks gap before rec 会省略掉,间隙锁会显示成 lock_mode X,插入意向锁会显示成 lock_mode X insert intention。譬如下面这个示例:
RECORD LOCKS space id 0 page no 307 n bits 72 index
PRIMARYof tabletest.testtrx id 50F lock_mode X
Record lock, heap no 1 PHYSICAL RECORD: n_fields 1; compact format; info bits 0
看起来像是 Next-key 锁,但是看下面的 heap no 1 表示这个记录是 supremum record(另外,infimum record 的 heap no 为 0),所以这个锁应该看作是一个间隙锁。
总结
这里东西起初只是知道概念,直到我最近遇到一起死锁事故,深入分析时才扯出来这么多的内容,本次探索最意外的收获是得知了MVCC实现中产生的两个概念:「当前读」和「快照读」。后续继续研究后再来聊聊MVCC吧(挖坑!
引用
- 14.7.2.1 Transaction Isolation Levels
- 14.7.1 InnoDB Locking
- 15.2.10. InnoDB事务模型和锁定
- 解决死锁之路 - 常见 SQL 语句的加锁分析
- Mysql 死锁场景一(insert on duplicate key)
- Mysql死锁如何排查:insert on duplicate死锁一次排查分析过程
- Bug #52020: InnoDB can still deadlock on just INSERT...ON DUPLICATE KEY
- 讲讲insert on duplicate key update 的死锁坑
- mysql批量insert数据锁表_mysql批量插入死锁问题分析(正序VS逆序)
- 如何阅读死锁日志
- MYSQL- Lock--gap before rec insert intention waiting:意向锁(IX)等待
- 详解 MySql InnoDB 中意向锁的作用