什么是分布式锁?
分布式锁有什么特性?
分布式锁需要注意什么?
如何实现分布式锁?
CAP定理
分布式系统(distributed system)正变得越来越重要。
而分布式系统的最大难点,就是各个节点的状态同步。
CAP 定理是这方面的基本定理,也是理解分布式系统的起点。
Consistency:一致性。
Availability:可用性。
Partition tolerance:分区容错。
一般来说,分区容错无法避免,所以基本都是保证AP或者CP,那为什么AC无法同时做到呢?
其实答案也比较简单,假设推理一下就好:
假设节点一 s1正常,但与节点二 s2之间的通信出现了错误。
如果需要保证一致性,那么当s1有写入时,只能等待s2恢复并同步数据之后,s2才能恢复读写操作,此段时间内,s2自然是无法保证可用性的;
反之亦然,当保证可用性时,一致性就无法保证。
PS. 现今大多数场景下,都是优先保证AP,退而求其次的只保证最终一致性。
什么是分布式锁
联系上文,分布式锁的出现,就是为了在很多场景中,控制程序的执行顺序,防止共享资源被多个线程同时访问。总结下,就是保证最终一致性的一种解决方案。
分布式锁的特性
1、互斥性:这个应该是分布式锁的基本特性,或者说也是锁的基本特性,保证资源(这里指共享代码段或者共享变量)同时只能有一个节点的某个线程访问
2、可重入性:同一个线程,允许重复多次加锁
3、锁超时:当锁超时,为了保证锁能正常使用,需要保证能够释放锁资源
4、非阻塞:支持获取锁的时候直接返回结果值(true or false),而不是在没有获取到锁的时候阻塞住线程的执行
5、公平锁与非公平锁:公平锁是指按照请求加锁的顺序获得锁,非公平锁请求加锁是无序的。
这些是分布式锁的常见特性,不一定都要满足,比如非阻塞特性,是可以看场景需要决定是否添加
如何实现分布式锁
常见的有三种方式
基于数据库实现分布式锁;
基于缓存(Redis等)实现分布式锁;
基于Zookeeper实现分布式锁;
基于数据库实现分布式锁
基于MySql实现分布式锁有三种方式,分别是基于唯一索引,悲观锁与乐观锁
基于MySql实现分布式锁主要是利用MySql自身的行锁机制,保证对于某一行,同时只能由一个线程对其查询或者更新(这就实现了分布式锁的最基本的特性:互斥性),而能够访问该行的线程即可以认为是获取到分布式锁的线程。
基于唯一索引实现
CREATE TABLE lock(
id int(11) NOT NULL AUTO_INCREMENT COMMENT ‘主键’,
lock_name varchar(64) NOT NULL DEFAULT ‘’ COMMENT ‘锁名’,
desc varchar(1024) NOT NULL DEFAULT ‘备注信息’,
update_time timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT ‘保存数据时间,自动生成’,
PRIMARY KEY (id),
UNIQUE KEY uidx_lock_name (lock_name) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT=‘锁定中的方法’;
获取锁执行insert语句,如果插入成功则说明可以成功获取到锁
insert into lock(lock_name,desc) values (‘lock_name’,‘desc’)
释放锁则执行delete语句
delete from lock where lock_name='lock_name'
1、利用数据库的唯一索引,天然实现唯一性
2、insert为非阻塞的,一旦插入失败就返回结果了,如果想要实现阻塞可以使用while循环;
3、要实现公平锁,可以引入一张表,记录因为插入失败而阻塞的线程,一旦锁被释放,被阻塞的线程可以根据插入的先后顺序来决定自己是否可以获取锁;
4、要实现可重入性,需要在锁表中增加一列,记录获取锁的服务节点信息与线程信息,获取锁的时候先查询数据库,如果当前机器的主机信息和线程信息在数据库可以查到的话,直接把锁分配给他就可以了;
5、要实现锁超时,需要在锁表增加一列,记录锁失效的时间,同时增加一个定时任务系统,定时扫描锁表中超时的记录,删除该条记录从而释放锁。
基于数据库排他锁实现
transaction begin
lock = sql("select * from resource_lock where resource_name = lockName for update")
if lock == null {
sql("insert into resource_lock(reosurce_name,owner) values (lockName, 'ip')")
}
业务逻辑 ...
事务完成时即锁释放
1、需要事务资源、并且"for update"时,是占用了数据库的链接在等待了,很浪费资源,
2、只能通过设置innodb_lock_wait_timeout控制全局的锁超时时间,默认是50s
3、锁重入难以实现
基于数据库乐观锁实现
transaction begin
lock = sql("select * from resource_lock where resource_name = lockName")
if lock == null {
sql("insert into resource_lock(reosurce_name,owner) values (lockName, 'ip')")
}
version = lock.version
业务逻辑 ...
count = sql("update resource_lock set version=version+1 where resource_name = lockName and version=#{version}");
if(count == 1) {
// 成功获取到分布式锁,可以提交本次事务
} else {
// 使用while重复执行select,update来获取分布式锁资源或者直接回滚本地事务
}
1、同样需要使用事务资源,只有当更新成功时提交事务,此时意味着没有其他人插入执行,从而保证一致性
2、乐观锁的基础是假设冲突不多,如果冲突一多,那么多个sql,事务资源等等都会是很严重的问题,所以需要特定场景才可以使用
基于缓存(Redis等)实现分布式锁
利用redis天然的支持分布式系统的特性以及某些命令的使用,可以较好的来实现分布式锁。redis的读写性能比较数据库来说也有极大的提升,目前也是一种较为流行的分布式锁解决方案。
SetNX命令实现分布式锁
SETNX key value 将key的值设置为value,当且仅当key不存在的时候
func getLock(redis redisClient, key string, uuid string, expireTime int32) bool {
ret = redis.setnx(key, uuid)
if (ret) {
// setnx再设置过期时间非原子操作,此时如果出问题,那将会无法释放锁,出现死锁
redis.expire(expireTime)
return true
}
return false
}
为了解决非原子操作,常用的方式有两种
- lua脚本
// 加锁脚本,KEYS[1] 要加锁的key,ARGV[1]是UUID随机值,ARGV[2]是过期时间
SCRIPT_LOCK = "if redis.call('setnx', KEYS[1], ARGV[1]) == 1 then redis.call('pexpire', KEYS[1], ARGV[2]) return 1 else return 0 end";
// 解锁脚本,KEYS[1]要解锁的key,ARGV[1]是UUID随机值
SCRIPT_UNLOCK = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";
- 设置value为锁过期时间
func getLock(redis redis.Client, key string, expire int32) {
expireTime = time() + expire; // 设置锁的过期时间
// 如果当前锁不存在,返回加锁成功
if (redis.setnx(key, expireTime)) {
return true;
}
// 如果锁存在,获取锁的过期时间
currentTime = redis.get(key);
if (currentTime != null && currentTime < time()) {
// 锁已过期,获取上一个锁的过期时间,并设置现在锁的过期时间
oldTime = redis.getSet(key, expireTime);
if (oldTime != null && oldTime == currentTime) {
// 考虑多线程并发的情况,只有一个线程的设置值和当前值相同,它才有权利加锁
return true;
}
}
// 其他情况,一律返回加锁失败
return false;
}
// 释放锁
func releaseLock(redis redis.Client, key string) {
redis.del(key);
}
这种会存在两个问题
- 过期时间可能被多个线程getSet 互相覆盖
- 线程可能会删除掉其他的锁
SET key value [EX seconds] [PX milliseconds] [NX|XX] 命令实现分布式锁
SET key value [EX seconds] [PX milliseconds] [NX|XX]
可选参数
从 Redis 2.6.12 版本开始, SET 命令的行为可以通过一系列参数来修改:
EX second :设置键的过期时间为 second 秒。 SET key value EX second 效果等同于 SETEX key second value 。
PX millisecond :设置键的过期时间为 millisecond 毫秒。 SET key value PX millisecond 效果等同于 PSETEX key millisecond value 。
NX :只在键不存在时,才对键进行设置操作。 SET key value NX 效果等同于 SETNX key value 。
XX :只在键已经存在时,才对键进行设置操作。
使用set命令,则可以将 NX 和 PX|EX 两个参数合并起来完成原子操作:
func getLock(key string, uuid string, expireTime int32) {
result = redis.set(key, uuid, "NX", "PX", expireTime);
if (result) {
return true;
}
return false;
}
// 而释放锁,可以使用lua脚本
script = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";
基于Zookeeper实现分布式锁
Zookeeper 是一种提供「分布式服务协调」的中心化服务,类似于Unix文件系统结构,可以看作一棵树,每个节点叫做ZNode。ZNode中可以存储数据。ZNode节点分为两种类型:
临时节点:当客户端和服务端断开连接后,所创建的Znode(节点)会自动删除
根据节点是否有序分为普通临时节点与有序临时节点
持久化节点:当客户端和服务端断开连接后,所创建的Znode(节点)不会删除
根据节点是否有序分为普通持久化节点与有序持久化节点
Zookeeper还提供了Watcher机制,Zookeeper允许用户在指定节点上注册一些Watcher,并且在一些特定事件触发的时候(比如节点存储信息改变/节点被删除/节点新增(删除)子节点等),ZooKeeper服务端会将事件通知到感兴趣的客户端上去,该机制是Zookeeper实现分布式协调服务的重要特性。
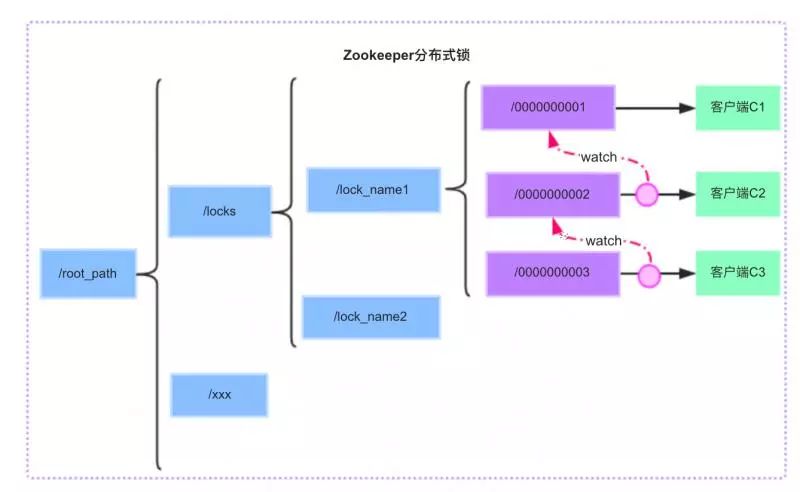
基于zookeeper的特性,可以实现分布式锁:
首先创建持久化节点/lock_name1,每当有客户端来访问/lock_name1节点,就在该节点下创建一个临时有序子节点,由于临时有序节点是递增的,所以总有一个临时有序节点的序号是最小的,那么这个序号最小的节点就可以获得分布式锁。而其他未获取到锁请求则通过Watcher机制监听上一个比自己序号小的节点。
1、客户端C1拿到/lock_name1下面所有的子节点,比较序号,发现自己序号最小,所以得到锁。
2、客户端C2拿到/lock_name1下面所有的子节点,比较序号,发现自己的序号不是最小的,所以客户端C2并不会获取到锁,而是监听比自己序号小的上一个节点C1的状态。
3、客户端C3拿到/lock_name1下面所有的子节点,比较序号,发现自己的序号不是最小的,所以客户端C3并不会获取到锁,而是监听比自己序号小的上一个节点C2的状态。
…
n、客户端C1执行完毕,释放锁资源,同时C1节点被删除,而C2监控到C1节点状态发生变化,比较之后发现自己的序号最小,所以可以获取锁。
总结:zookeeper实现分布式锁主要也是使用了zookeeper的自身的特性,即使同一时刻多个请求过来,创建的节点的序号也是递增的且不会重复。而利用监听机制可以保证锁被释放之后其他节点可以获取到该信息从而有机会去获取锁。
总结
以上几种方式,各有优劣,但我们在面临某一个需求时,最重要的是根据实际的需要来选择,而不是盲目的追求全面,加油,共勉