整理几个常见的缓存方面的问题
缓存的必要性
- 增强用户体验,减少用户等待时间;
- 降低服务器压力;
- 降低APP客户端的网络流量消耗;
从业务考虑,缓存更多是为了增强用户体验
从技术考虑,缓存更多是为了提高系统的响应速度
当然于此同时,我们要面临的就是引入缓存所带来的问题:
缓存穿透、缓存击穿、缓存雪崩
缓存穿透
什么是缓存穿透
正常情况下,我们去查询数据都是存在。那么请求去查询一条压根儿数据库中根本就不存在的数据,也就是缓存和数据库都查询不到这条数据,但是请求每次都会打到数据库上面去。这种查询不存在数据的现象我们称为缓存穿透。
带来的问题
试想一下,如果有黑客会对你的系统进行攻击,拿一个不存在的id去查询数据,会产生大量的请求到数据库去查询。可能会导致你的数据库由于压力过大而宕掉。
如何解决
- 参数校验
对于一部分不应该存在的参数,我们理应提前限制住,fail fast - 缓存空值
这种做法有点类似于一种降级策略;对于不存在的值,如果我们能够往内存中填充一个空值,那么就不会导致每次查询都打到数据库,当然,这种情况下需要设置过期时间,并且需要仔细的评估业务需要而设置过期时间 - 布隆过滤器(BloomFilter)
布隆过滤器适用于数据量较大时使用,如果数据量较小,那么弄一个hash表或者bit数组之类的即可
布隆过滤器是巴顿.布隆于一九七零年提出的,核心就是一个超大的位数组和多个哈希函数,如下图:
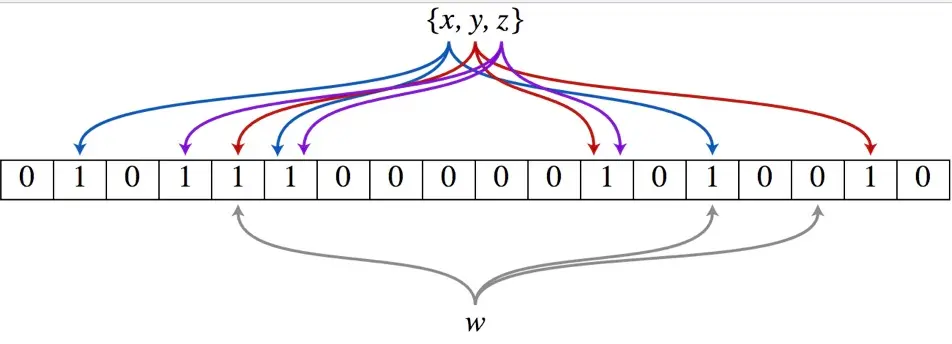
查询:需要判断一个数据w是否存在时,用多个hash函数求得w的hash值,然后在这些位上查看是否都有1,均为1则证明元素有可能存在,如果存在0则证明肯定不存在
添加:添加元素则将多个hash值位置上的位置为1
布隆过滤器是有错误率的,不过很小,所以,只要不是零错误的场景,都是可以满足需求的,感兴趣可以看下这位大佬的错误率计算:Bloom Filter概念和原理
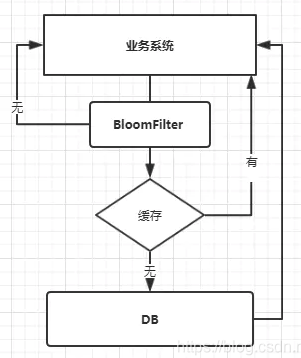
使用布隆过滤器后的流程图如下:
这里有一个golang的代码实现bloomfilter
type Filter struct {
lock sync.RWMutex
bits []uint64
keys []uint64
m uint64 // number of bits the "bits" field should recognize
n uint64 // number of inserted elements
}
缓存击穿
什么是缓存击穿
在平常高并发的系统中,大量的请求同时查询一个key时,此时这个key正好失效了,就会导致大量的请求都打到数据库上面去。这种现象我们称为缓存击穿。
带来的问题
会造成某一时刻数据库请求量过大,压力剧增。
如何解决
这种场景,一般我们会限制同一个key的多次数据回捞,例如使用singleflight(单飞)等工具。
单飞主要有两个重要的结构体
// call is an in-flight or completed singleflight.Do call
// call 表示一个正在执行的或已完成的函数调用,存储调用的接口、报错一些标记等等,
type call struct {
// 可以看到,singleflight实现中用到了WaitGroup来保证只有一个goroutinue去回捞
wg sync.WaitGroup
// These fields are written once before the WaitGroup is done
// and are only read after the WaitGroup is done.
// 记录结果,在WaitGroup完成之前,只会写入一次,重点在此了
val interface{}
err error
// forgotten indicates whether Forget was called with this call's key
// while the call was still in flight.
// 用来标识执行完成之后结果立马删除还是保留在singleflight中
forgotten bool
// These fields are read and written with the singleflight
// mutex held before the WaitGroup is done, and are read but
// not written after the WaitGroup is done.
// 这个字段记录执行次数,更新时机是发起请求,waitGroup执行完成‘之前’
dups int
// 用来记录DoChan中需要返回的数据
chans []chan<- Result
}
// Group represents a class of work and forms a namespace in
// which units of work can be executed with duplicate suppression.
// 用来记录已经存在的对某key的请求和对应的实际请求函数(call)的映射
type Group struct {
mu sync.Mutex // protects m 加锁保护m,并不是用锁来保证只有一个goroutinue去回捞
m map[string]*call // lazily initialized 懒加载
}
详情可以自己看下源码,或者看下我自己写的这篇文章源码杂货铺:singleflight
缓存雪崩
什么是缓存雪崩
缓存雪崩的情况是说,当某一时刻发生大规模的缓存失效的情况,比如你的缓存服务宕机了,会有大量的请求进来直接打到DB上面。结果就是DB撑不住挂掉。
带来的问题
会造成某一时刻数据库请求量过大,压力剧增。
如何解决
(1)事前:
- 均匀过期:设置不同的过期时间,让缓存失效的时间尽量均匀,避免相同的过期时间导致缓存雪崩,造成大量数据库的访问。
- 分级缓存:第一级缓存失效的基础上,访问二级缓存,每一级缓存的失效时间都不同。
- 热点数据缓存永远不过期。
永不过期实际包含两层意思:
物理不过期,针对热点key不设置过期时间
逻辑过期,把过期时间存在key对应的value里,如果发现要过期了,通过一个后台的异步线程进行缓存的构建
- 保证Redis缓存的高可用,防止Redis宕机导致缓存雪崩的问题。可以使用 主从+ 哨兵,Redis集群来避免 Redis 全盘崩溃的情况。
(2)事中:
- 互斥锁:在缓存失效后,通过互斥锁或者队列来控制读数据写缓存的线程数量,比如某个key只允许一个线程查询数据和写缓存,其他线程等待。这种方式会阻塞其他的线程,此时系统的吞吐量会下降
- 使用熔断机制,限流降级。当流量达到一定的阈值,直接返回“系统拥挤”之类的提示,防止过多的请求打在数据库上将数据库击垮,至少能保证一部分用户是可以正常使用,其他用户多刷新几次也能得到结果。
(3)事后:
- 开启Redis持久化机制,尽快恢复缓存数据,一旦重启,就能从磁盘上自动加载数据恢复内存中的数据。
缓存预热和缓存降级
这两个并非问题,而是两个策略,为了解决一些问题
什么是缓存预热
缓存预热是指系统上线后,提前将相关的缓存数据加载到缓存系统。避免在用户请求的时候,先查询数据库,然后再将数据缓存的问题,用户直接查询事先被预热的缓存数据。
如果不进行预热,那么Redis初始状态数据为空,系统上线初期,对于高并发的流量,都会访问到数据库中, 对数据库造成流量的压力。
缓存预热方案:
- 数据量不大的时候,工程启动的时候进行加载缓存动作;
- 数据量大的时候,设置一个定时任务脚本,进行缓存的刷新;
- 数据量太大的时候,优先保证热点数据进行提前加载到缓存。
什么是缓存降级
缓存降级是指缓存失效或缓存服务器挂掉的情况下,不去访问数据库,直接返回默认数据或访问服务的内存数据。降级一般是有损的操作,所以尽量减少降级对于业务的影响程度。
缓存降级方案:
在项目实战中通常会将部分热点数据缓存到服务的内存中,这样一旦缓存出现异常,可以直接使用服务的内存数据,从而避免数据库遭受巨大压力。
引用
缓存技术方案
缓存三种模式
理解与解决缓存穿透、缓存击穿、缓存雪崩、热点数据失效问题
布隆过滤器(Bloom Filter)的原理和实现
Bloom Filter概念和原理
【缓存】缓存穿透、缓存并发、热点缓存解决方案
缓存穿透与热点缓存等问题的解决方案
缓存击穿、缓存并发和缓存雪崩
Redis的缓存雪崩、缓存击穿、缓存穿透与缓存预热、缓存降级
面试Redis——缓存并发 缓存雪崩 缓存穿透