分布式链路追踪相信大家都不陌生,很好用,可以帮我们观察系统结构,清晰调用链路,快速定位排查问题等等。分布式追踪有多种实现方案,我熟悉的是jaeger,那jaeger是如何实现的呢?我们一起深入学习下吧
背景
随着微服务的发展,我们的系统变得越来越复杂,越来越庞大,这个时候,分布式追踪应运而生,旨在解决跨进程事务的描述和分析。这里不得不提下Google Dapper这篇论文,这篇论文各种Tracer的基础,大家可以看下打个基础。
Opentracing 协议数据模型
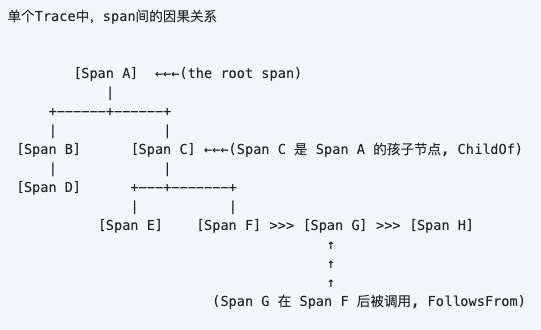
这张图想必了解过Opentracing的都会比较熟悉。Span相当于是Trace基础数据单元,Trace相当于一个或多个span的有向无环图,而spanContext则是Span中的重要元素,承担起串联零个或者多个有关联的Span的职责
这就是Opentracing标准中三个重要类型的关联关系
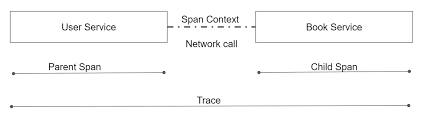
Tracer
Tracer接口用来创建Span,以及处理如何处理Inject(serialize) 和 Extract (deserialize),用于跨进程边界传递,它可以创建span,提取、注入spanContext
接口定义如下,这是实现一个Tracer的最小子集了
type Tracer interface{
// 用于新开一个Span,名称不多说;上下级context关系在于StartSpanOption这个参数集合中的
// `SpanReference`, 用于表明Span之间的关系
StartSpan(operationName string, opts ...StartSpanOption) Span
// 将SpanContext 用预定的 format 格式,注入到 carrier 中
Inject(sm SpanContext, format interface{}, carrier interface{}) error
// 将SpanContext 用预定的 format 格式,从 carrier 中提取出来
Extract(format interface{}, carrier interface{}) (SpanContext, error)
}
另外会有两个比较重要的特殊Tracer,globaltracer 和 NoopTracer
- globaltracer
工程项目中,会有一个globaltracer,统一的确定服务中的Tracer,防止链路追踪因多个Tracer不兼容等问题无法生效 - NoopTracer
如果我们没有对Tracer进行初始化,则默认情况下,采用opentracing-go底层标准下的默认空Tracer——NoopTracer,这个是在实现OpenTracing标准API库时,必须要做的。NoopTracer可以被用作控制或者测试时,进行无害的inject注入等。
1、noopSpanContext是在SpanReference中使用,它代表SpanContext上下文传输tracer时的span获取。并携带Baggage信息;ForeachBaggageItem(func(k, v string) bool){}
2、noopSpan实现了Span interface。方法实现全部为空;
3、noopTracer实现了Tracer interface,包括StartSpan、Inject和Extract三个方法;全部为空实现;
Span
当Span结束后(span.finish()),除了通过Span获取SpanContext外,下列其他所有方法都不允许被调用。包含功能如下:
- 获取Span的SpanContext
- 结束Span
- 为Span设置Tag
- Log结构化数据
- 设置baggage(随行数据)元素
- 获取baggage
type Span interface{
// Span执行单元结束
Finish()
// 带结束时间和日志记录列表信息,Span执行单元结束;也就是说结束时间可以业务指定; 日志列表也可以直接添加; 目前还不知道这个的使用场景;
FinishWithOptions(opts FinishOptions)
// 把Span的Baggage封装成SpanContext
Context() SpanContext
// 设置Span的操作名称
SetOperationName(operationName string) Span
// 设置Span Tag
SetTag(key string, value interface{}) Span
// 设置Span的log.Field列表;
// span.LogFields(
// log.String("event", "soft error"),
// )
LogFields(fields ...log.Field)
// key-value列表={"event": "soft error", "type": "cache timeout", "waited.millis":1500}
LogKV(alternatingKeyValues ...interface{})
// LogFields与LogKV类似,只是前者已封装好;
// 设置span的Baggage:key-value, 用于跨进程上下文传输
SetBaggageItem(restrictedKey, value string) Span
// 通过key获取value;
BaggageItem(restrictedKey string) string
// 获取Span所在的调用链tracer
Tracer() Tracer
// 废弃,改用LogFields 或者 LogKV
LogEvent(event string)
// 同上
LogEventWithPayload(event string, payload interface{});
// 同上
Log(data LogData)
}
ext/tags
OpenTracing APIs中已经定义了很多常见的tag,而在Span的定义中只有写入Tag的方法SetTag,应该是想让实现协议的Tracer自己写读方法吧。
SetTag(key string, value interface{}) Span
SpanContext
相对于OpenTracing中其他的功能,SpanContext更多的是一个“概念”。也就是说,OpenTracing实现中,需要重点考虑,并提供一套自己的API。 OpenTracing的使用者仅仅需要在创建Span、向传输协议Inject(注入)和从传输协议中Extract(提取)时使用SpanContext
// Span之间跨进程调用时,会使用SpanContext传输Baggage携带信息。通过context标准库实现
type contextKey struct{}
var activeSpanKey = contextKey{}
// 封装span到context中
func ContextWithSpan(ctx context.Context, span Span) context{
return context.WithValue(ctx, activeSpanKey, span)
}
// 从ctx中通过activeSpanKey取出Span,这里可以看到不同服务的activeSpanKey值,是相同的,上面的DEMO可以说明。
func SpanFromContext(ctx context.Context) Span{
val:=ctx.Value(activeSpanKey)
if sp, ok := val.(Span); ok{
return sp
}
return nil
}
// 通过context上下文的activeSpanKey,我们可以获得Span,并创建新的span
func startSpanFormContextWithTracer(ctx context.Context, tracer Tracer, operationName string, opts ...StartSpanOption) (Span, context.Context){
// 首先从上下文看是否能够获取到span,如果获取不到,再创建tracer和span;
if parentSpan:= SpanFromContext(ctx); parentSpan !=nil {
opts = append(opts, ChildOf(parentSpan.Context()))
}
span := tracer.StartSpan(operationName, opts...)
return span, ContextWithSpan(ctx, span)
}
Baggage读写
之前提到的baggage读写,实现上就是在所谓的Carrier中存放kv。目前三种Key,分别对应byte流,TextMap 和 httpHeader。而Carrier就是对应于Key代表类型的一个"运输者"
定义:
byte流直接使用io.Writer 和 io.Reader即可,而后两种类型,需要实现下面的接口
type TextMapWriter interface {
Set(key, val string)
}
type TextMapReader interface {
ForeachKey(handler func(key, value string) error) error
}
baggage实现如下:
// TextMap
type TextMapCarrier map[string]string
func (c TextMapCarrier) ForeachKey(handler func(key, val string) error) error{
for k, v := range c{
if err := handler(k, v); err!=nil{
return err
}
}
return nil
}
func (c TextMapCarrier) Set(key, val string){
c[key] = val
}
// Http.Header
type HTTPHeadersCarrier http.Header
func (c HTTPHeadersCarrier) Set(key, val string){
h:= http.Header(c)
h.Add(key, val)
}
func (c HTTPHeadersCarrier) ForeachKey(handler func(key, value string) error) error{
for k, vals:= range c{
for _, v := range vals{
if err:= handler(k, v); err !=nil{
return errr
}
}
}
return nil
}
以上就是Opentracing中做出的主要约定,具体的实现则需要各个tracer各显神通了,下面我们来看看jaeger的实现。
Jaeger
了解了Opentracing,我们来看jaeger的实现。
先看一张架构图:
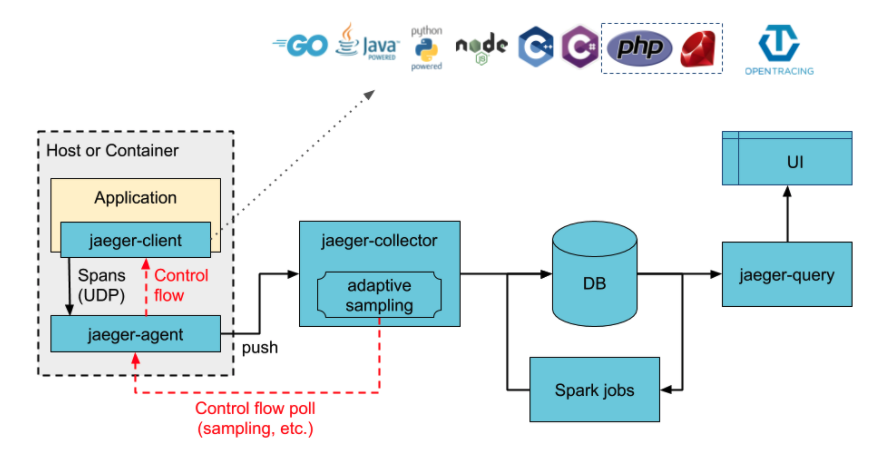
这里DB只是一个代指,默认没有存储时,Jaeger的数据就会放在内存中,掉电就没了,还是比较危险的,比如我们项目中使用的是ES,可以看下加入ES之后的图:

通常做法,我们会在服务中集成一个jaeger的client,这个用来处理Tracer,上报上下文链路信息;agent作为一个代理,帮助服务整合、发送信息到collector;collector则负责收集、汇总、整理数据;这里如果有ES或其他组件做存储,则再插入一个环节,collector汇总数据,放入es存储;query负责去存储中查询数据,没有es等存储,则collector会直接将数据放入内存中,供query查询。
Client
我们用的是jaeger-client-go,下面我们主要从注入、提取、上报三块看下源码
注入
可以看到,这里主要就是把我们上面提到的Baggage中的参数放到了Carrier中,而这个Carrier上面也提到了,是根据Value类型而定的,所以这里定义是interface{}
// 以TextMap类型的value为例
// Inject implements Injector of TextMapPropagator
func (p *TextMapPropagator) Inject(
sc SpanContext,
abstractCarrier interface{},
) error {
textMapWriter, ok := abstractCarrier.(opentracing.TextMapWriter)
if !ok {
return opentracing.ErrInvalidCarrier
}
// Do not encode the string with trace context to avoid accidental double-encoding
// 不需要额外编码,防止混乱
// if people are using opentracing < 0.10.0. Our colon-separated representation
// of the trace context is already safe for HTTP headers.
// 0.10.0版本之前,冒号分隔的参数,对HTTP头是安全的
textMapWriter.Set(p.headerKeys.TraceContextHeaderName, sc.String())
for k, v := range sc.baggage {
// 用添加一个前缀
safeKey := p.addBaggageKeyPrefix(k)
safeVal := p.encodeValue(v)
textMapWriter.Set(safeKey, safeVal)
}
return nil
}
提取
相对应的,提取过程主要就是把Carrier中的数据放回到Baggage中,同样根据Value类型有三个种类的Extract函数
// Extract implements Extractor of TextMapPropagator
func (p *TextMapPropagator) Extract(abstractCarrier interface{}) (SpanContext, error) {
textMapReader, ok := abstractCarrier.(opentracing.TextMapReader)
if !ok {
return emptyContext, opentracing.ErrInvalidCarrier
}
var ctx SpanContext
var baggage map[string]string
err := textMapReader.ForeachKey(func(rawKey, value string) error {
// 这里会有一个处理,需要注意,避开小坑
key := strings.ToLower(rawKey) // TODO not necessary for plain TextMap
// 初始化Tracer时可以给出一些headers的配置
// 可以决定这里是否会有一些特定key的特殊处理
if key == p.headerKeys.TraceContextHeaderName {
var err error
safeVal := p.decodeValue(value)
if ctx, err = ContextFromString(safeVal); err != nil {
return err
}
} else if key == p.headerKeys.JaegerDebugHeader {
ctx.debugID = p.decodeValue(value)
} else if key == p.headerKeys.JaegerBaggageHeader {
if baggage == nil {
baggage = make(map[string]string)
}
for k, v := range p.parseCommaSeparatedMap(value) {
baggage[k] = v
}
} else if strings.HasPrefix(key, p.headerKeys.TraceBaggageHeaderPrefix) {
if baggage == nil {
baggage = make(map[string]string)
}
safeKey := p.removeBaggageKeyPrefix(key)
safeVal := p.decodeValue(value)
baggage[safeKey] = safeVal
}
return nil
})
if err != nil {
// 自定义metrics指标 底层用的atomic包
p.metrics.DecodingErrors.Inc(1)
return emptyContext, err
}
if !ctx.traceID.IsValid() && ctx.debugID == "" && len(baggage) == 0 {
return emptyContext, opentracing.ErrSpanContextNotFound
}
// 数据塞到baggage中
ctx.baggage = baggage
return ctx, nil
}
上报
每个Span都有它自己的生命周期,而在span执行Finish方法时候,才会触发上报,上代码
// Finish implements opentracing.Span API
// After finishing the Span object it returns back to the allocator unless the reporter retains it again,
// so after that, the Span object should no longer be used because it won't be valid anymore.
func (s *Span) Finish() {
s.FinishWithOptions(opentracing.FinishOptions{})
}
// FinishWithOptions implements opentracing.Span API
func (s *Span) FinishWithOptions(options opentracing.FinishOptions) {
if options.FinishTime.IsZero() {
options.FinishTime = s.tracer.timeNow()
}
// 可以通过函数参数处理 FinishTime、LogRecords、BulkLogData(deprecated)
s.observer.OnFinish(options)
// 加锁算时长
s.Lock()
s.duration = options.FinishTime.Sub(s.startTime)
ctx := s.context
s.Unlock()
// 取样器是否完工
if !ctx.isSamplingFinalized() {
decision := s.tracer.sampler.OnFinishSpan(s)
s.applySamplingDecision(decision, true)
}
// IsSampled returns whether this trace was chosen for permanent storage
// by the sampling mechanism of the tracer.
// 上面是这个方法的原注释,意思比较清楚了,看是不是选择了需要持久化存储
if ctx.IsSampled() {
s.Lock()
s.fixLogsIfDropped()
if len(options.LogRecords) > 0 || len(options.BulkLogData) > 0 {
// Note: bulk logs are not subject to maxLogsPerSpan limit
if options.LogRecords != nil {
s.logs = append(s.logs, options.LogRecords...)
}
for _, ld := range options.BulkLogData {
s.logs = append(s.logs, ld.ToLogRecord())
}
}
s.Unlock()
}
// call reportSpan even for non-sampled traces, to return span to the pool
// and update metrics counter
// 调用上报Span的方法
s.tracer.reportSpan(s)
}
// IsSampled returns whether this trace was chosen for permanent storage
// by the sampling mechanism of the tracer.
func (c SpanContext) IsSampled() bool {
return c.samplingState.isSampled()
}
下面是真正的上报的代码了,也是一个基于chan的实现
数据填入时机有调用report和close时
数据真正的通过udp(通常都是用udp)发送是定时的
const (
// 默认队列长度
defaultQueueSize = 100
// 默认发送udp间隔
defaultBufferFlushInterval = 1 * time.Second
)
...
// NewRemoteReporter creates a new reporter that sends spans out of process by means of Sender.
// Calls to Report(Span) return immediately (side effect: if internal buffer is full the span is dropped).
// Periodically the transport buffer is flushed even if it hasn't reached max packet size.
// Calls to Close() block until all spans reported prior to the call to Close are flushed.
func NewRemoteReporter(sender Transport, opts ...ReporterOption) Reporter {
options := reporterOptions{}
for _, option := range opts {
option(&options)
}
// 初始化刷数据间隔
if options.bufferFlushInterval <= 0 {
options.bufferFlushInterval = defaultBufferFlushInterval
}
if options.logger == nil {
options.logger = log.NullLogger
}
if options.metrics == nil {
options.metrics = NewNullMetrics()
}
// 初始化队列长度
if options.queueSize <= 0 {
options.queueSize = defaultQueueSize
}
reporter := &remoteReporter{
reporterOptions: options,
sender: sender,
queue: make(chan reporterQueueItem, options.queueSize),
reporterStats: new(reporterStats),
}
if receiver, ok := sender.(reporterstats.Receiver); ok {
receiver.SetReporterStats(reporter.reporterStats)
}
// go出去的协程,处理队列
go reporter.processQueue()
return reporter
}
// Report implements Report() method of Reporter.
// It passes the span to a background go-routine for submission to Jaeger backend.
// If the internal queue is full, the span is dropped and metrics.ReporterDropped counter is incremented.
// If Report() is called after the reporter has been Close()-ed, the additional spans will not be
// sent to the backend, but the metrics.ReporterDropped counter may not reflect them correctly,
// because some of them may still be successfully added to the queue.
// 主动调用上报处,select实现阻塞发送
func (r *remoteReporter) Report(span *Span) {
select {
// Need to retain the span otherwise it will be released
case r.queue <- reporterQueueItem{itemType: reporterQueueItemSpan, span: span.Retain()}:
atomic.AddInt64(&r.queueLength, 1)
default:
r.metrics.ReporterDropped.Inc(1)
r.reporterStats.incDroppedCount()
}
}
// Close implements Close() method of Reporter by waiting for the queue to be drained.
// Span关闭被动上报处
func (r *remoteReporter) Close() {
r.logger.Debugf("closing reporter")
if swapped := atomic.CompareAndSwapInt64(&r.closed, 0, 1); !swapped {
r.logger.Error("Repeated attempt to close the reporter is ignored")
return
}
r.sendCloseEvent()
_ = r.sender.Close()
}
// waitGroup实现的阻塞发送
func (r *remoteReporter) sendCloseEvent() {
wg := &sync.WaitGroup{}
wg.Add(1)
item := reporterQueueItem{itemType: reporterQueueItemClose, close: wg}
r.queue <- item // if the queue is full we will block until there is space
atomic.AddInt64(&r.queueLength, 1)
wg.Wait()
}
// processQueue reads spans from the queue, converts them to Thrift, and stores them in an internal buffer.
// When the buffer length reaches batchSize, it is flushed by submitting the accumulated spans to Jaeger.
// Buffer also gets flushed automatically every batchFlushInterval seconds, just in case the tracer stopped
// reporting new spans.
func (r *remoteReporter) processQueue() {
// flush causes the Sender to flush its accumulated spans and clear the buffer
// 包了一个处理函数,感觉没啥必要?
flush := func() {
if flushed, err := r.sender.Flush(); err != nil {
r.metrics.ReporterFailure.Inc(int64(flushed))
r.logger.Error(fmt.Sprintf("failed to flush Jaeger spans to server: %s", err.Error()))
} else if flushed > 0 {
r.metrics.ReporterSuccess.Inc(int64(flushed))
}
}
timer := time.NewTicker(r.bufferFlushInterval)
for {
select {
// 定时刷数据
case <-timer.C:
flush()
// 预处理待发送数据
case item := <-r.queue:
atomic.AddInt64(&r.queueLength, -1)
switch item.itemType {
case reporterQueueItemSpan:
span := item.span
if flushed, err := r.sender.Append(span); err != nil {
r.metrics.ReporterFailure.Inc(int64(flushed))
r.logger.Error(fmt.Sprintf("error reporting Jaeger span %q: %s", span.OperationName(), err.Error()))
} else if flushed > 0 {
r.metrics.ReporterSuccess.Inc(int64(flushed))
// to reduce the number of gauge stats, we only emit queue length on flush
r.metrics.ReporterQueueLength.Update(atomic.LoadInt64(&r.queueLength))
r.logger.Debugf("flushed %d spans", flushed)
}
// 按引用层级,没有引用时候就是表明当前位置是自己所在层级了
span.Release()
// chan关闭,清理,注意资源释放,细节
case reporterQueueItemClose:
timer.Stop()
flush()
item.close.Done()
return
}
}
}
}
Agent
agent的功能是收集client发出的数据,简单处理后发送给collector,完成数据上报
端口
agent默认会监听三个端口
- 处理zipkin的compact格式udp端口
- 处理jaeger的compact格式udp端口
- 处理jaeger的binary格式udp端口
均会用thrift协议传输数据
var defaultProcessors = []struct {
model Model
protocol Protocol
port int
}{
{model: "zipkin", protocol: "compact", port: ports.AgentZipkinThriftCompactUDP},
{model: "jaeger", protocol: "compact", port: ports.AgentJaegerThriftCompactUDP},
{model: "jaeger", protocol: "binary", port: ports.AgentJaegerThriftBinaryUDP},
}
接收
从agent的run函数中可以追踪到,数据是放在了chan *ReadBuf类型的dataChan中
这里有一个细节,Agent的服务队列是有长度限制的(default 1000),如果堆积超过1000个,Agent就会毫不怜悯的把数据丢掉,这个做法是在这种场景下的一种很明智的做法,舍小顾大
// TBufferedServer is a custom thrift server that reads traffic using the transport provided
// and places messages into a buffered channel to be processed by the processor provided
type TBufferedServer struct {
// NB. queueLength HAS to be at the top of the struct or it will SIGSEV for certain architectures.
// See https://github.com/golang/go/issues/13868
queueSize int64
// 接收数据的接口
dataChan chan *ReadBuf
maxPacketSize int
maxQueueSize int
serving uint32
transport ThriftTransport
readBufPool *sync.Pool
metrics struct {
// Size of the current server queue
QueueSize metrics.Gauge `metric:"thrift.udp.server.queue_size"`
// Size (in bytes) of packets received by server
PacketSize metrics.Gauge `metric:"thrift.udp.server.packet_size"`
// Number of packets dropped by server
PacketsDropped metrics.Counter `metric:"thrift.udp.server.packets.dropped"`
// Number of packets processed by server
PacketsProcessed metrics.Counter `metric:"thrift.udp.server.packets.processed"`
// Number of malformed packets the server received
ReadError metrics.Counter `metric:"thrift.udp.server.read.errors"`
}
}
...
// NewTBufferedServer creates a TBufferedServer
// 接收服务的new方法
func NewTBufferedServer(
transport ThriftTransport,
maxQueueSize int,
maxPacketSize int,
mFactory metrics.Factory,
) (*TBufferedServer, error) {
dataChan := make(chan *ReadBuf, maxQueueSize)
// 处理后的数据放入的 `sync.Pool`
var readBufPool = &sync.Pool{
New: func() interface{} {
return &ReadBuf{bytes: make([]byte, maxPacketSize)}
},
}
res := &TBufferedServer{dataChan: dataChan,
transport: transport,
maxQueueSize: maxQueueSize,
maxPacketSize: maxPacketSize,
readBufPool: readBufPool,
serving: stateInit,
}
metrics.MustInit(&res.metrics, mFactory, nil)
return res, nil
}
...
// Serve initiates the readers and starts serving traffic
func (s *TBufferedServer) Serve() {
defer close(s.dataChan)
// cas方式控制服务的启停,并没有使用chan实现
if !atomic.CompareAndSwapUint32(&s.serving, stateInit, stateServing) {
return // Stop already called
}
for s.IsServing() {
readBuf := s.readBufPool.Get().(*ReadBuf)
n, err := s.transport.Read(readBuf.bytes)
if err == nil {
readBuf.n = n
s.metrics.PacketSize.Update(int64(n))
// 阻塞式等数据
select {
case s.dataChan <- readBuf:
s.metrics.PacketsProcessed.Inc(1)
s.updateQueueSize(1)
default:
s.readBufPool.Put(readBuf)
s.metrics.PacketsDropped.Inc(1)
}
} else {
s.readBufPool.Put(readBuf)
s.metrics.ReadError.Inc(1)
}
}
}
接收到之后,需要简单的进行一个处理
// processBuffer reads data off the channel and puts it into a custom transport for
// the processor to process
func (s *ThriftProcessor) processBuffer() {
for readBuf := range s.server.DataChan() {
protocol := s.protocolPool.Get().(thrift.TProtocol)
payload := readBuf.GetBytes()
protocol.Transport().Write(payload)
s.logger.Debug("Span(s) received by the agent", zap.Int("bytes-received", len(payload)))
// 只有一些很简单的校验,日志打印,错误记录等
if ok, err := s.handler.Process(context.Background(), protocol, protocol); !ok {
s.logger.Error("Processor failed", zap.Error(err))
s.metrics.HandlerProcessError.Inc(1)
}
s.protocolPool.Put(protocol)
// 塞入数据到pool
s.server.DataRecd(readBuf) // acknowledge receipt and release the buffer
}
}
发送
处理完放好之后,就是发送了
func (p *agentProcessorEmitBatch) Process(ctx context.Context, seqId int32, iprot, oprot thrift.TProtocol) (success bool, err thrift.TException) {
args := AgentEmitBatchArgs{}
var err2 error
// 按协议读出数据
if err2 = args.Read(ctx, iprot); err2 != nil {
iprot.ReadMessageEnd(ctx)
return false, thrift.WrapTException(err2)
}
iprot.ReadMessageEnd(ctx)
tickerCancel := func() {}
_ = tickerCancel
// 批量发出,发出后释放资源,细节
if err2 = p.handler.EmitBatch(ctx, args.Batch); err2 != nil {
tickerCancel()
return true, thrift.WrapTException(err2)
}
tickerCancel()
return true, nil
}
collector
collector主要负责的就是汇总数据,保存数据,所以这里一定会看到一些并发支持的代码
接收
接收数据,汇总数据,不多说,上代码
我们先来看下如何做的接收消息的并发支持
func (q *BoundedQueue) Produce(item interface{}) bool {
if atomic.LoadInt32(&q.stopped) != 0 {
q.onDroppedItem(item)
return false
}
select {
// 接收到消息后,扔进队列,下面会有处理的地方
case q.items <- item:
atomic.AddInt32(&q.size, 1)
return true
default:
if q.onDroppedItem != nil {
q.onDroppedItem(item)
}
return false
}
}
这里会消费扔进队列的数据
// StartConsumersWithFactory creates a given number of consumers consuming items
// from the queue in separate goroutines.
func (q *BoundedQueue) StartConsumersWithFactory(num int, factory func() Consumer) {
q.workers = num
q.factory = factory
// waitGroup 做的等待,保持goroutinue统一
var startWG sync.WaitGroup
// 默认workers有50个
for i := 0; i < q.workers; i++ {
q.stopWG.Add(1)
startWG.Add(1)
go func() {
startWG.Done()
defer q.stopWG.Done()
consumer := q.factory()
queue := *q.items
// 基于 select + chan 做的轮训等待 和 启停机制
for {
select {
case item, ok := <-queue:
if ok {
q.size.Sub(1)
// 执行消费
consumer.Consume(item)
} else {
// channel closed, finish worker
return
}
case <-q.stopCh:
// the whole queue is closing, finish worker
return
}
}
}()
}
startWG.Wait()
}
写入数据
在 github.com/jaegertracing/jaeger/plugin/storage 中可以看到很多种存储介质,es、memory、cassandra等等,分别去处理不同存储介质时的保存等工作
以内存为例
// WriteSpan writes the given span
func (m *Store) WriteSpan(ctx context.Context, span *model.Span) error {
m.Lock()
defer m.Unlock()
if _, ok := m.operations[span.Process.ServiceName]; !ok {
m.operations[span.Process.ServiceName] = map[spanstore.Operation]struct{}{}
}
spanKind, _ := span.GetSpanKind()
operation := spanstore.Operation{
Name: span.OperationName,
SpanKind: spanKind,
}
if _, ok := m.operations[span.Process.ServiceName][operation]; !ok {
m.operations[span.Process.ServiceName][operation] = struct{}{}
}
m.services[span.Process.ServiceName] = struct{}{}
if _, ok := m.traces[span.TraceID]; !ok {
m.traces[span.TraceID] = &model.Trace{}
// if we have a limit, let's cleanup the oldest traces
if m.config.MaxTraces > 0 {
// we only have to deal with this slice if we have a limit
m.index = (m.index + 1) % m.config.MaxTraces
// do we have an item already on this position? if so, we are overriding it,
// and we need to remove from the map
if m.ids[m.index] != nil {
delete(m.traces, *m.ids[m.index])
}
// update the ring with the trace id
m.ids[m.index] = &span.TraceID
}
}
// 使用traceID串起来spans
m.traces[span.TraceID].Spans = append(m.traces[span.TraceID].Spans, span)
return nil
}
这里暂时列出了这些相对比较关键的步骤源码,大家感兴趣的可以继续探索
总结
第一次从一个完整的项目工具方案的角度看源码学习,jaeger client上报数据、collector处理数据等处的并发玩法,以及chan的运用,还有就是agent丢消息策略等等,这些都很值得我们学习和借鉴。希望能够多多阅读此类代码,运用到自己的工作中去,提高自己的工程水平。共勉
引用
理论学习
Dapper,大规模分布式系统的跟踪系统
opentracing文档中文版 ( 翻译 ) 吴晟
OpenTracing文档
OpenTracing语义标准
OpenTracing语义惯例
OpenTracing语义标准规范及实现
jaeger-docs
opentracing jaeger 整合及源码分析
opentracing/opentracing-go源码
Jaeger源码分析——窥视分布式系统实现
工程实战
基于Zap Context实现日志服务链路追踪
Gin 通过中间件接入 Jaeger 收集 Tracing
Golang 上手GORM V2 + Opentracing链路追踪优化CRUD体验(源码阅读)
jaegertracing/jaeger源码
jaegertracing/jaeger-client-go源码
gin-gonic/examples
Distributed Tracing with Apache Kafka and Jaeger
Distributed tracing with Kafka message headers
geek981108/go-jaeger-kafka-client
dlmiddlecote/sqlstats
johejo/promredis
使用 ElasticSearch 作为 Jaeger 的存储并且进行聚合计算
jaeger linux 部署
docker compose安装Jaeger 1.18