MySQL学的不好,补补课
Btree索引
数据结构为B+树,结构特点为
- 树形结构:由根、分支、叶三级节点组成,其中分支节点可以有多层。
- 多分支结构:跟节点和分支节点可以由多个子节点(超过2),因此树的深度较小
- 数据或数据指针都在叶子节点上,根、分支节点上只有索引,叶子节点之间有双向链表
Btree索引的特点如下:
数据结构利用率高、定位高效
因其分支较多,树的深度小,往往千万数据也只是3层,即千万数据中查询一个数据,只需读取三次即可定位
平衡扩张
在数据扩张过程中,会用额外的开销处理数据,使树保持平衡,并且保证叶子节点都在同一深度
单叶子节点数据插入:

叶子节点拆分:
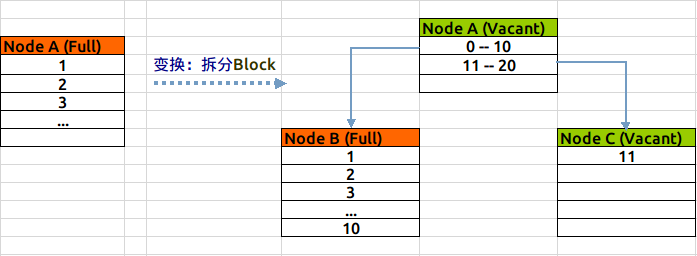
叶子节点增加:
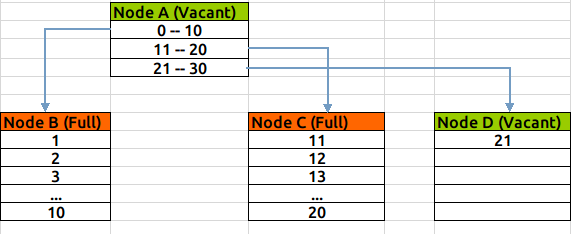
叶子节点深度增加:
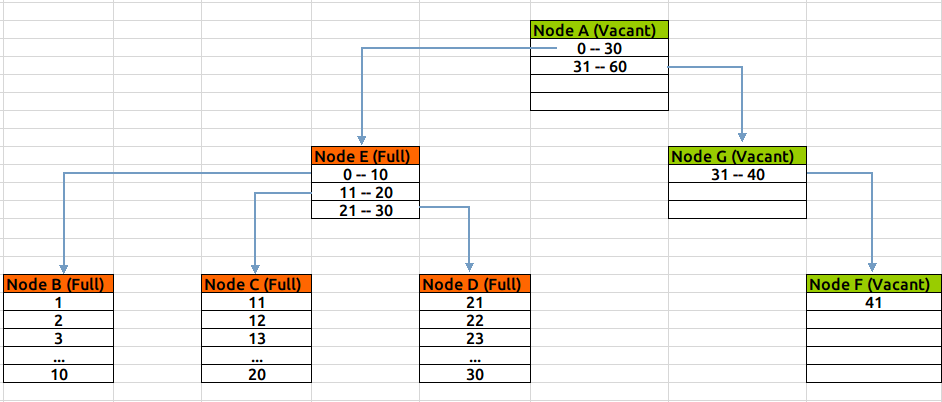
Btree索引的问题如下:
单一方向扩展引起的索引竞争(Index Contention)
若索引列使用sequence或者timestamp这类只增不减的数据类型。这种情况下Btree索引的增长方向总是不变的,不断的向右边扩展,因为新插入的值永远是最大的。
当一个最大值插入到叶子节点中后,需要向上更新分支节点、根节点的最大值,并且可能因为块写满后执行块拆分。
如果此时并发插入多个最大值,则最右边索引数据块的的更新与拆分都会存在争抢,影响效率。在AWR报告中可以通过检测enq: TX – index contention事件的时间来评估争抢的影响。解决此类问题可以使用Reverse Index解决,不过会带来新的问题。
索引失效(Index Browning)
我们知道当表中的数据删除后,索引上对应的索引值是不会删除的,特别是在一性次删除大批量数据后,会造成大量的失效叶子节点挂到索引树上。此时如果对该列取max(),则会去相邻叶子节点中查找数据,拖慢速度
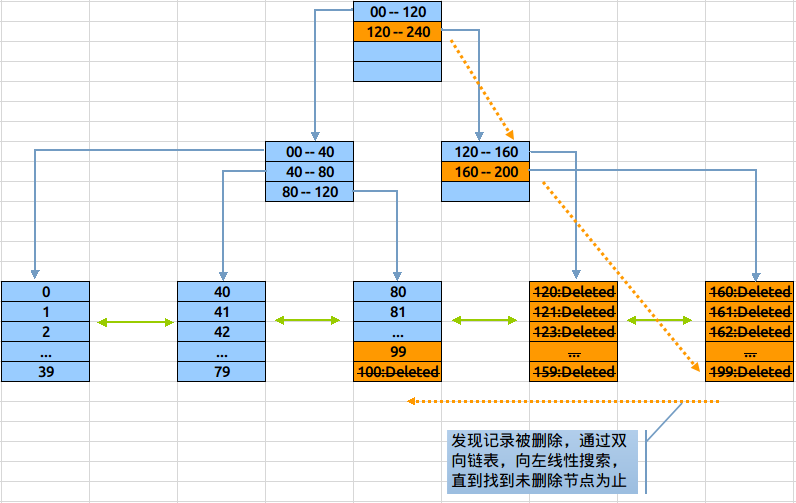
oracle中有一个方案,使用coalesce语句来整理这些失效叶子节点到freelist中,就可以避免这些问题。理论上oracle中这步操作是可以自动完成的,但在实际中一次性大量删除数据后,oracle在短时间内是反应不过来的。
HASH索引
Hash索引只能用于对等比较,例如=,<=>(相当于=)操作符。由于是一次定位数据,不像BTree索引需要从根节点到枝节点,最后才能访问到页节点这样多次IO访问,所以检索效率远高于BTree索引。
但同样的,限制也会有很多
hash索引缺点
- 不能避免读取行
哈希索引只包含哈希值和行指针,而不存储字段值,所以不能使用索引中的值来避免读取行。不过,访问内存中的行的速度很快,所以大部分情况下这一点对性能的影响并不明显。 - 无法用于排序
哈希索引数据并不是按照索引值顺序存储的,所以也就无法用于排序。 - 无法使用部分索引列匹配查找
哈希索引也不支持部分索引列匹配查找,因为哈希索引始终是使用索引列的全部内容来计算哈希值的。 - 只支持等值查找
哈希索引只支持等值比较查询,包括=、IN()、<=>(注意<>和<=>是不同的操作) - 存在Hash冲突
访问哈希索引的数据非常快,除非有很多哈希冲突(不同的索引列值却有相同的哈希值)。当出现哈希冲突的时候,存储引擎必须遍历链表中所有的行指针,逐行进行比较,直到找到所有符合条件的行。
同时,当哈希冲突很多的时候,一些索引维护操作的代价也会很高。
总结
当我们对比了这两种索引的特性之后,此时两种索引的对比也就很明显了,
HASH索引往往只适用于某些特定场景,不过HASH结构是一个值得关注的结构,很多时候可以用它来空间换时间
BTREE索引则适应面更广,一般来说我们都会选用它