map是我们开发过程中常常会使用到的数据结构,那么
map是如何实现的?
map是否线程安全?
map有哪些需要注意的地方?
map
首先,如果要学习map的细节,推荐移步曹大的文章:
golang-notes/map.md
这里不会详细讨论map的各种实现细节,只是简单的挑一些点来赘述下(基本都是参考于曹大的这篇文章,侵删)
map数据结构:
const (
// 一个 bucket 最多能放的元素数
bucketCntBits = 3
bucketCnt = 1 << bucketCntBits
// load factor = 13/2
loadFactorNum = 13
loadFactorDen = 2
// 超过这两个 size 的对应对象,会被转为指针
maxKeySize = 128
maxValueSize = 128
// data offset should be the size of the bmap struct, but needs to be
// aligned correctly. For amd64p32 this means 64-bit alignment
// even though pointers are 32 bit.
dataOffset = unsafe.Offsetof(struct {
b bmap
v int64
}{}.v)
// tophash 除了放正常的高 8 位的 hash 值
// 还会在空闲、迁移时存储一些特征的状态值
// 所以合法的 tophash(指计算出来的那种),最小也应该是 4
// 小于 4 的表示的都是我们自己定义的状态值
empty = 0 // cell is empty
evacuatedEmpty = 1 // cell is empty, bucket is evacuated.
evacuatedX = 2 // key/value is valid. Entry has been evacuated to first half of larger table.
evacuatedY = 3 // same as above, but evacuated to second half of larger table.
minTopHash = 4 // minimum tophash for a normal filled cell.
// flags
iterator = 1 // there may be an iterator using buckets
oldIterator = 2 // there may be an iterator using oldbuckets
hashWriting = 4 // a goroutine is writing to the map
sameSizeGrow = 8 // the current map growth is to a new map of the same size
// sentinel bucket ID for iterator checks
noCheck = 1<<(8*sys.PtrSize) - 1
)
// A header for a Go map.
type hmap struct {
count int // map 中的元素个数,必须放在 struct 的第一个位置,因为 内置的 len 函数会从这里读取
flags uint8
B uint8 // log_2 of # of buckets (最多可以放 loadFactor * 2^B 个元素,再多就要 hashGrow 了)
noverflow uint16 // overflow 的 bucket 的近似数
hash0 uint32 // hash seed
buckets unsafe.Pointer // 2^B 大小的数组,如果 count == 0 的话,可能是 nil
oldbuckets unsafe.Pointer // 一半大小的之前的 bucket 数组,只有在 growing 过程中是非 nil
nevacuate uintptr // progress counter for evacuation (buckets less than this have been evacuated)
extra *mapextra // 当 key 和 value 都可以 inline 的时候,就会用这个字段
}
type mapextra struct {
// 如果 key 和 value 都不包含指针,并且可以被 inline(<=128 字节)
// 使用 extra 来存储 overflow bucket,这样可以避免 GC 扫描整个 map
// 然而 bmap.overflow 也是个指针。这时候我们只能把这些 overflow 的指针
// 都放在 hmap.extra.overflow 和 hmap.extra.oldoverflow 中了
// overflow 包含的是 hmap.buckets 的 overflow 的 bucket
// oldoverflow 包含扩容时的 hmap.oldbuckets 的 overflow 的 bucket
overflow *[]*bmap
oldoverflow *[]*bmap
// 指向空闲的 overflow bucket 的指针
nextOverflow *bmap
}
// bucket 本体
type bmap struct {
// tophash 是 hash 值的高 8 位
tophash [bucketCnt]uint8
// keys
// values
// overflow pointer
}
map的初始化
map的使用很简单,初始化的代码为:make(map[k]v, size) 或者 make(map[k]v)
一般情况下,这里size < 8时,map的初始化就会使用makemap_small,否则使用makemap当然最终的结果会受逃逸分析影响,这里感兴趣的童鞋可以自行研究下
// 文件路径src/runtime/map.go
// makemap_small implements Go map creation for make(map[k]v) and
// make(map[k]v, hint) when hint is known to be at most bucketCnt
// at compile time and the map needs to be allocated on the heap.
// 小于等于8个元素时,可能就会使用这个函数,直接new一个hmap
func makemap_small() *hmap {
h := new(hmap)
h.hash0 = fastrand()
return h
}
...
// make(map[k]v, hint)
// 如果编译器认为 map 和第一个 bucket 可以直接创建在栈上,h 和 bucket 可能都是非空
// h != nil,可以直接在 h 内创建 map
// 如果 h.buckets != nil,其指向的 bucket 可以作为第一个 bucket 来使用
func makemap(t *maptype, hint int, h *hmap) *hmap {
// 在 64 位系统上 hmap 结构体大小为 48 字节
// 32 位系统上是 28 字节
if sz := unsafe.Sizeof(hmap{}); sz != 8+5*sys.PtrSize {
println("runtime: sizeof(hmap) =", sz, ", t.hmap.size =", t.hmap.size)
throw("bad hmap size")
}
if hint < 0 || hint > int(maxSliceCap(t.bucket.size)) {
hint = 0
}
// 初始化 hmap
if h == nil {
// runtime.newobject 在堆上分配内存
h = (*hmap)(newobject(t.hmap))
}
h.hash0 = fastrand()
// 按照提供的元素个数,找一个可以放得下这么多元素的 B 值
B := uint8(0)
for overLoadFactor(hint, B) {
B++
}
h.B = B
// 分配初始的 hash table
// 如果 B == 0,buckets 字段会由 mapassign 来 lazily 分配
// 因为如果 hint 很大的话,对这部分内存归零会花比较长时间
if h.B != 0 {
var nextOverflow *bmap
h.buckets, nextOverflow = makeBucketArray(t, h.B)
if nextOverflow != nil {
h.extra = new(mapextra)
h.extra.nextOverflow = nextOverflow
}
}
return h
}
可以看到初始分配内存是根据是否传入hint决定,而频繁扩容向来是一个我们不希望看到的开销,所以如果能提前确定size,请一定要传入
map的元素访问
访问过程在曹大的文章中有图解,可以前往观看,我这边简单描述下,hash计算后,会利用低5位确定数据属于哪个bucket,高8位用来确定bucket中元素的位置
func mapaccess2(t *maptype, h *hmap, key unsafe.Pointer) (unsafe.Pointer, bool) {
// map 为空,或者元素数为 0,直接返回未找到
if h == nil || h.count == 0 {
return unsafe.Pointer(&zeroVal[0]), false
}
if h.flags&hashWriting != 0 {
throw("concurrent map read and map write")
}
alg := t.key.alg
// 不同类型的 key,所用的 hash 算法是不一样的
// 具体可以参考 algarray
hash := alg.hash(key, uintptr(h.hash0))
// 如果 B = 3,那么结果用二进制表示就是 111
// 如果 B = 4,那么结果用二进制表示就是 1111
m := bucketMask(h.B)
// 按位 &,可以 select 出对应的 bucket
b := (*bmap)(unsafe.Pointer(uintptr(h.buckets) + (hash&m)*uintptr(t.bucketsize)))
// 会用到 h.oldbuckets 时,说明 map 发生了扩容
// 这时候,新的 buckets 里可能还没有老的内容
// 所以一定要在老的里面找,否则有可能发生“消失”的诡异现象
if c := h.oldbuckets; c != nil {
if !h.sameSizeGrow() {
// 说明之前只有一半的 bucket,需要除 2
m >>= 1
}
oldb := (*bmap)(unsafe.Pointer(uintptr(c) + (hash&m)*uintptr(t.bucketsize)))
if !evacuated(oldb) {
b = oldb
}
}
// tophash 取其高 8bit 的值
top := tophash(hash)
for ; b != nil; b = b.overflow(t) {
// 一个 bucket 在存储满 8 个元素后,就再也放不下了
// 这时候会创建新的 bucket
// 挂在原来的 bucket 的 overflow 指针成员上
for i := uintptr(0); i < bucketCnt; i++ {
// 循环对比 bucket 中的 tophash 数组
// 如果找到了相等的 tophash,那说明就是这个 bucket 了
if b.tophash[i] != top {
continue
}
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if t.indirectkey {
k = *((*unsafe.Pointer)(k))
}
if alg.equal(key, k) {
v := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
if t.indirectvalue {
v = *((*unsafe.Pointer)(v))
}
return v, true
}
}
}
// 所有 bucket 都没有找到,返回零值和 false
return unsafe.Pointer(&zeroVal[0]), false
}
这里有几点可能会比较重要
- 这里是读取操作,这时会根据
hashWriting标识判断是否发生了并发读写 oldbuckets是扩容前老map的地址,需要从中查询数据,防止扩容尚未完成时获取不到数据overflow可能会有多个,需要遍历查询数据是否在其中
map的扩缩容过程
震惊!golang map不会缩容!
扩容
这里具体流程代码较多,不粘贴了,大家可以去曹大文章看下
先说一下触发扩容函数hashGrow的两个触发点
- 桶快满了:元素个数 >= 桶个数 * 6.5
- 桶太多了:bucket 总数 < 2 ^ 15 时,如果 overflow 的 bucket 总数 >= bucket 的总数
第一种,会去对bucket数组扩容一倍
第二种,会触发移动数据,使bucket数据紧凑,并不会增多bucket
这里简述下流程:
- 是否需要真的扩容,置局部变量
bigger,决定元素数量是否扩张(加到B上) 和 常量flags,看是否保持size - 扩容时需要将当前buckets放到
oldbuckets,并将nevacuate和noverflow标志位置为0,意指此map需要移动数据,含义参见上面数据结构
map的注意点
还有一些注意点我们需要了解
- 无论键还是值,如果size 大于 128字节时,会转为指针
- 对nil的map赋值,会panic
- map线程不安全(并发读写会有不可recover的错误
- map的键需要是可比较的类型
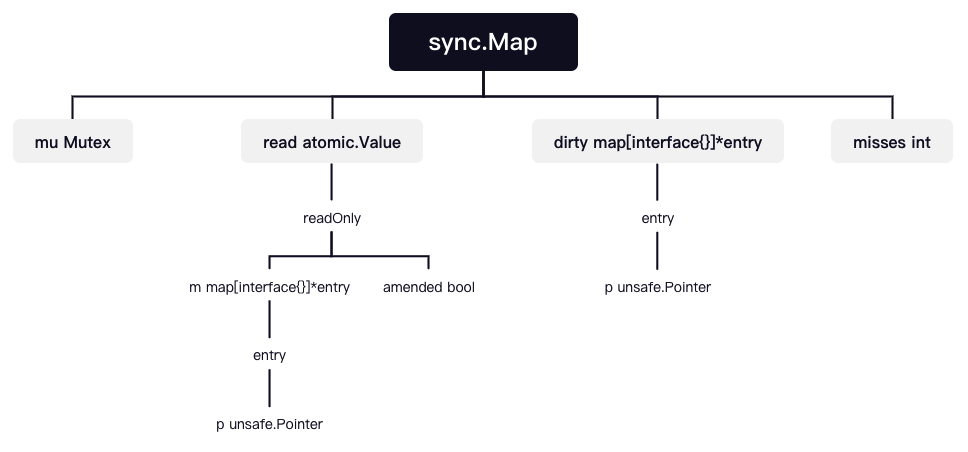
sync.Map
那么下面我们先看看sync.Map的数据结构
数据结构
type Map struct {
// 互斥锁,用于锁定dirty map
mu Mutex
// 优先读map,支持原子操作,注释中有readOnly不是说read是只读,而是它在面对存储的元素时只读
// read实际上在需要升级dirty的情况下也写的操作
read atomic.Value
// dirty是一个当前最新的map,允许读写
dirty map[interface{}]*entry
// 主要记录read读取不到数据加锁读取read map以及dirty map的次数,
// 当misses等于dirty的长度时,会将dirty复制到read
misses int
}
type readOnly struct {
m map[interface{}]*entry
// 如果数据在dirty中但没有在read中,该值为true,作为修改标识
amended bool
}
type entry struct {
// 1、nil: 表示为被删除,调用Delete()可以将read map中的元素置为nil
// 2、expunged: 也是表示被删除,但是该键只在read而没有在dirty中,
// 这种情况出现在将read复制到dirty中,即复制的过程会先将nil标记为expunged,
// 然后不将其复制到dirty
// 3、其他: 表示存着真正的数据
// *interface{}
p unsafe.Pointer
}
为了更直观,可以看下这个图
Load函数
func (m *Map) Load(key interface{}) (value interface{}, ok bool) {
// 第一次检测元素是否存在
read, _ := m.read.Load().(readOnly)
e, ok := read.m[key]
if !ok && read.amended {
// 为dirty map 加锁
m.mu.Lock()
// 第二次检测元素是否存在,主要防止在加锁的过程中,dirty map转换成read map,从而导致读取不到数据
read, _ = m.read.Load().(readOnly)
e, ok = read.m[key]
if !ok && read.amended {
// 从dirty map中获取是为了应对read map中不存在的新元素
e, ok = m.dirty[key]
// 不论元素是否存在,均需要记录miss数,以便dirty map升级为read map
// 为什么可以无视read中是否可以存在的数据,关键在于read.amended字段的控制,详情可以看 Store 函数中 dirtyLocked 函数。
m.missLocked()
}
// 解锁
m.mu.Unlock()
}
// 元素不存在直接返回
if !ok {
return nil, false
}
return e.load()
}
func (m *Map) missLocked() {
// misses自增1
m.misses++
// 判断dirty map是否可以升级为read map
if m.misses < len(m.dirty) {
return
}
// dirty map升级为read map
m.read.Store(readOnly{m: m.dirty})
// dirty map 清空
m.dirty = nil
// misses重置为0
m.misses = 0
}
func (e *entry) load() (value interface{}, ok bool) {
p := atomic.LoadPointer(&e.p)
// 元素不存在或者被删除,则直接返回
if p == nil || p == expunged {
return nil, false
}
return *(*interface{})(p), true
}
为了便于理解,我们来个流程图看看
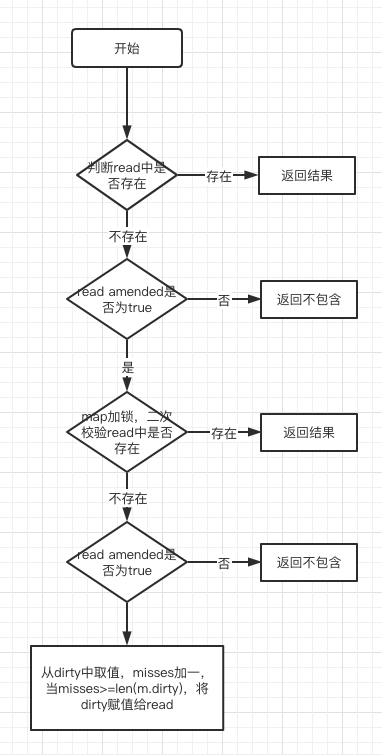
可以看出流程上在尽力的避免加锁,尽可能的优化访问速度
Store函数
func (m *Map) Store(key, value interface{}) {
// 如果read存在这个键,并且这个entry没有被标记删除,尝试直接写入,写入成功,则结束
// 第一次检测
read, _ := m.read.Load().(readOnly)
if e, ok := read.m[key]; ok && e.tryStore(&value) {
return
}
// dirty map锁
m.mu.Lock()
// 第二次检测
read, _ = m.read.Load().(readOnly)
if e, ok := read.m[key]; ok {
// unexpungelocc确保元素没有被标记为删除
// 判断元素被标识为删除
if e.unexpungeLocked() {
// 这个元素之前被删除了,这意味着有一个非nil的dirty,这个元素不在里面.
m.dirty[key] = e
}
// 更新read map 元素值
e.storeLocked(&value)
} else if e, ok := m.dirty[key]; ok {
// 此时read map没有该元素,但是dirty map有该元素,并需修改dirty map元素值为最新值
e.storeLocked(&value)
} else {
// read.amended==false, 说明 刚初始化 或者 dirty 升级过了,此时需要将 read 中元素 复制一份到dirty, 保证新的 read 是 dirty 的子集,这样 dirty 才能无所顾忌的升级为 read
// 当有 read 中不存在的新值插入时,才会触发此处逻辑
// dirtyLocked 函数把 read 中元素往 dirty 复制了一份,并把 read.amended 置为了true,表明 dirty 中存在了 read 中不存在的元素,并且 dirty 已经完全覆盖了 read 中的元素,方便其他地方做判断
if !read.amended {
m.dirtyLocked()
// 设置read.amended==true,说明dirty map有数据
m.read.Store(readOnly{m: read.m, amended: true})
}
// 设置元素进入dirty map,此时dirty map拥有read map和最新设置的元素
m.dirty[key] = newEntry(value)
}
// 解锁,有人认为锁的范围有点大,假设read map数据很大,那么执行m.dirtyLocked()会耗费花时间较多,完全可以在操作dirty map时才加锁,这样的想法是不对的,因为m.dirtyLocked()中有写入操作
m.mu.Unlock()
}
func (e *entry) tryStore(i *interface{}) bool {
// 获取对应Key的元素,判断是否标识为删除
p := atomic.LoadPointer(&e.p)
if p == expunged {
return false
}
for {
// cas尝试写入新元素值
if atomic.CompareAndSwapPointer(&e.p, p, unsafe.Pointer(i)) {
return true
}
// 判断是否标识为删除
p = atomic.LoadPointer(&e.p)
if p == expunged {
return false
}
}
}
func (e *entry) unexpungeLocked() (wasExpunged bool) {
return atomic.CompareAndSwapPointer(&e.p, expunged, nil)
}
func (m *Map) dirtyLocked() {
if m.dirty != nil {
return
}
read, _ := m.read.Load().(readOnly)
m.dirty = make(map[interface{}]*entry, len(read.m))
for k, e := range read.m {
// 如果标记为nil或者expunged,则不复制到dirty map
if !e.tryExpungeLocked() {
m.dirty[k] = e
}
}
}
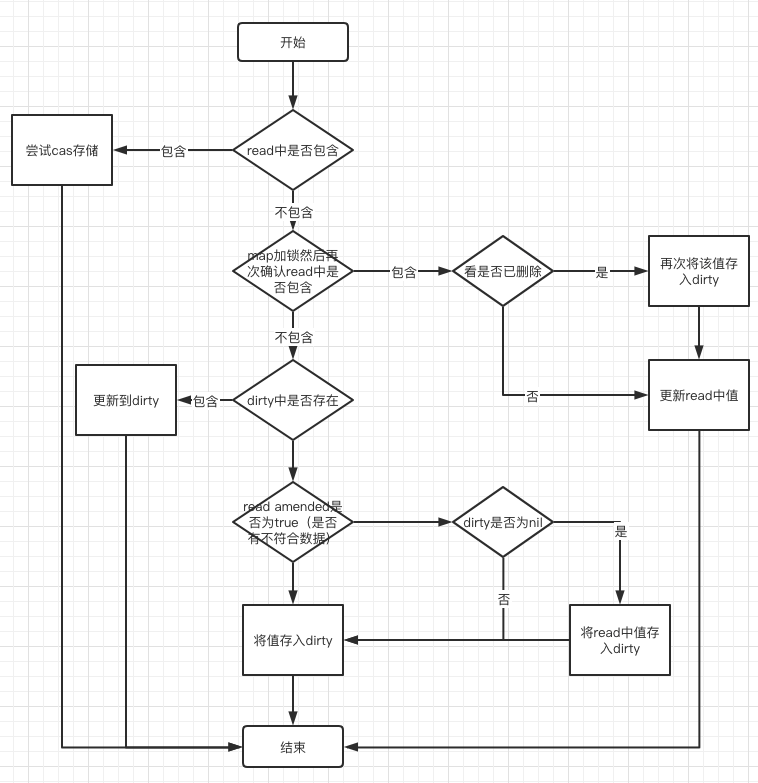
Delete函数
func (m *Map) Delete(key interface{}) {
// 第一次检测
read, _ := m.read.Load().(readOnly)
e, ok := read.m[key]
if !ok && read.amended {
m.mu.Lock()
// 第二次检测
read, _ = m.read.Load().(readOnly)
e, ok = read.m[key]
if !ok && read.amended {
// 不论dirty map是否存在该元素,都会执行删除
delete(m.dirty, key)
}
m.mu.Unlock()
}
if ok {
// 如果在read中,则将其标记为删除(nil)
e.delete()
}
}
func (e *entry) delete() (hadValue bool) {
for {
p := atomic.LoadPointer(&e.p)
if p == nil || p == expunged {
return false
}
if atomic.CompareAndSwapPointer(&e.p, p, nil) {
return true
}
}
}
这里需要注意的是,read中删除时会将元素置为nil,而不是像dirty中直接删除,这个是为了避免后续访问此元素时不需要再去dirty中查询,那样会需要加锁,成本较高
Range函数
func (m *Map) Range(f func(key, value interface{}) bool) {
// 第一检测
read, _ := m.read.Load().(readOnly)
// read.amended=true,说明dirty map包含所有有效的元素(含新加,不含被删除的),使用dirty map
if read.amended {
// 第二检测
m.mu.Lock()
read, _ = m.read.Load().(readOnly)
if read.amended {
// 使用dirty map并且升级为read map
read = readOnly{m: m.dirty}
m.read.Store(read)
m.dirty = nil
m.misses = 0
}
m.mu.Unlock()
}
// 一贯原则,使用read map作为读
for k, e := range read.m {
v, ok := e.load()
// 被删除的不计入
if !ok {
continue
}
// 函数返回false,终止
if !f(k, v) {
break
}
}
}
可以看到,range中会有将dirty升级为read的操作,这个也是为了range函数的结果尽量的正确,当然,这里并不是一开始就加锁,所以依然会存在并发问题
注意点
1、double-check
double-check技术是lock free编程中常用的手法, 更详细的内容可以参考 Wiki: Double-checked locking。
尤其Load这段代码中, double-check是必须的, 原因是并发执行下, dirty 会被提升为 read (发生在而在 !ok&&read.amended 代码之间), 从而在dirty中访问不到, 但read中访问到。
2、m.missLocked()
这个函数会在misses == len(dirty)时,将dirty升级为read,从而让读取数据的流程变短,提高效率
3、空间换时间
通过冗余的两个数据结构(read、dirty),read为只读数据,避免了读写冲突,减少加锁对性能的影响
4、延迟删除
删除一个键值只是打标记,只有在提升dirty的时候才清理删除的数据,也是为了减少性能影响
引用
src/runtime/map.go
golang-notes/map.md
golang-map是线程安全的吗?
Go 1.9 sync Map 源码阅读笔记
你不得不知道的sync.Map源码分析
Sync.Map 源码分析
Wiki: Double-checked locking