其演进历史及意义是什么?epoll的核心机制是什么?为什么windows上epoll不够用?
IO模型演进
阻塞IO
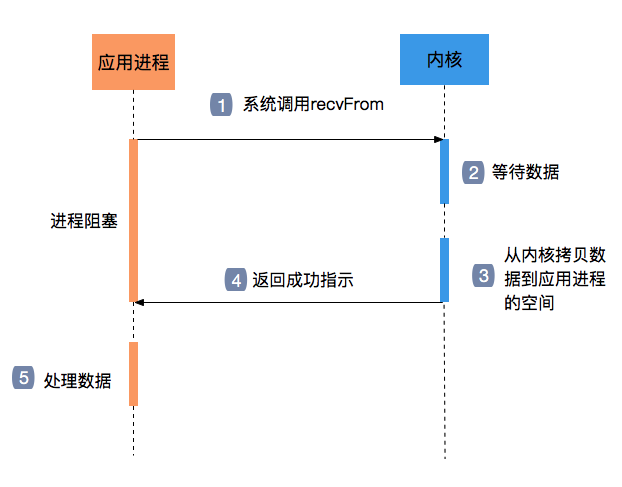
阻塞IO很好理解,就是处理过程中,过程是设定好的,比如先读取数据,等待完成,再写入数据,等待完成,处理完毕。
在这个过程中,如果读不到或者写不了,就无法往下进行,程序卡住;并且,读写时候都无法再去做其他的事情
非阻塞IO
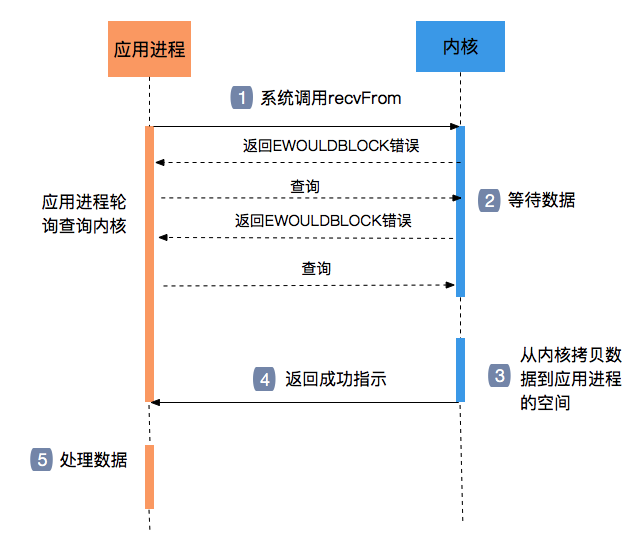
改为非阻塞之后,无论是读和写,开始执行后不会一直等待,而是可以隔一段去做一次查询,比如轮询,这样程序就不再需要阻塞在一个地方,相对灵活的处理数据。
但这里还是会有问题,在轮询查询时候,程序很可能空转,造成忙等;并且在读和写的处理过程中,依然是无法再做其他的工作
IO多路复用
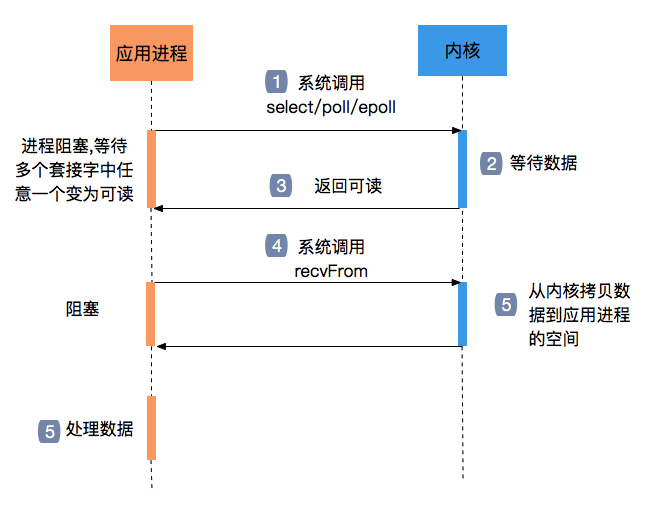
IO多路复用就是通过一个进程可以监视多个描述符,一旦某个描述符就绪,就通知应用程序进行相应的读写操作。目前常用的有 select、poll、 epoll三种实现方式。
这个时候,就不再需要一直轮询的去查询,而是把这个工作交给内核函数完成,也就不需要忙等了
信号驱动IO
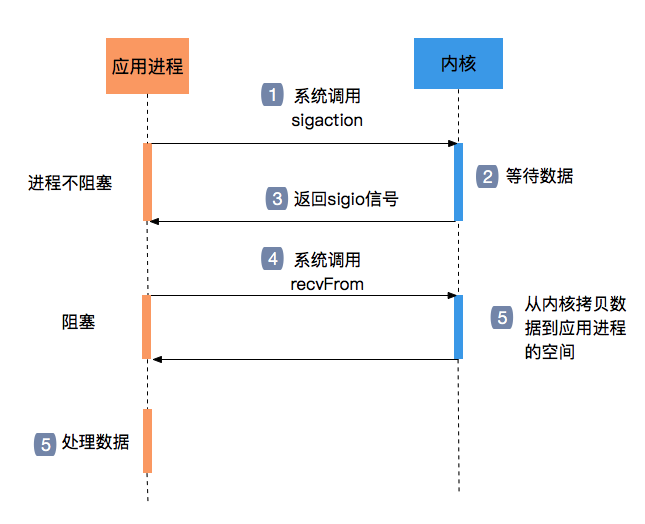
信号驱动IO有点类似与MQ,发送者发出消息后,继续做其他事情,无需阻塞,而消费者则再接受消息后再开始执行处理,只是在信号驱动IO中,发送者是系统本身,发出的mq消息是一个系统信号,而用户程序只扮演了消费者的身份,通过数据拷贝拿到消息体
异步IO
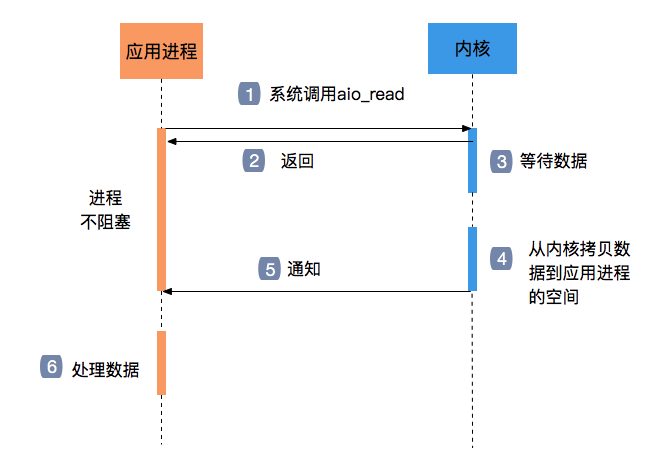
异步IO最初是因为epoll无法满足windows的需求而出现的,当然,无法满足的原因是Windows在IO的前后加入了大量的类似hook操作,拖慢了速度。与之相对的,在linux上epoll目前还是work well的
异步IO就是用户程序主动的调起一个系统操作,之后并不会阻塞;系统调用完成后会发回通知,用户程序之后再进行后续处理
select 源码学习
int select (int n, fd_set *readfds,
fd_set *writefds,
fd_set *exceptfds,
struct timeval *timeout);
struct timeval {
long tv_sec; //秒
long tv_usec; //毫秒
};
select最终是通过底层驱动对应设备文件的poll函数来查询是否有可用资源(可读或者可写),如果没有则睡眠。
fd_set
在讲select机制之前,先来认知一下参数中的一个结构体fd_set,代码如下所示。
#include <sys/select.h>
#define FD_SETSIZE 1024
#define NFDBITS (8 * sizeof(unsigned long))
#define __FDSET_LONGS (FD_SETSIZE/NFDBITS)
typedef struct {
unsigned long fds_bits[__FDSET_LONGS];
} fd_set;
void FD_SET(int fd, fd_set *fdset) //将fd添加到fdset
void FD_CLR(int fd, fd_set *fdset) //从fdset中删除fd
void FD_ISSET(int fd, fd_set *fdset) //判断fd是否已存在fdset
void FD_ZERO(fd_set *fdset) //初始化fdset内容全为0
fd_set是一个文件描述符fd的集合,由于每个进程可打开的文件描述符默认值为1024,fd_set可记录的fd个数上限也是为1024个。 从下面代码可知,fd_set采用位图bitmap算法,位图是一个比较经典的算法,此处创建一个大小为32的long型数组,每一个bit代表一个0~1023区间的数字。 可通过上述的4个FD_XXX()宏来操作fd_set数组。
相关操作方法
//记录可读、可写、异常 的输入和输出结果信息
typedef struct {
unsigned long *in, *out, *ex;
unsigned long *res_in, *res_out, *res_ex;
} fd_set_bits;
// 将用户空间的ufdset拷贝到内核空间fdset
static inline
int get_fd_set(unsigned long nr, void __user *ufdset, unsigned long *fdset)
{
nr = FDS_BYTES(nr);
if (ufdset)
return copy_from_user(fdset, ufdset, nr) ? -EFAULT : 0;
memset(fdset, 0, nr);
return 0;
}
// 将内核fdset拷贝到用户空间的ufdset
static inline unsigned long __must_check
set_fd_set(unsigned long nr, void __user *ufdset, unsigned long *fdset)
{
if (ufdset)
return __copy_to_user(ufdset, fdset, FDS_BYTES(nr));
return 0;
}
//将fdset内容清零
static inline
void zero_fd_set(unsigned long nr, unsigned long *fdset)
{
memset(fdset, 0, FDS_BYTES(nr));
}
do_select
int do_select(int n, fd_set_bits *fds, struct timespec *end_time)
{
ktime_t expire, *to = NULL;
struct poll_wqueues table;
poll_table *wait;
int retval, i, timed_out = 0;
u64 slack = 0;
rcu_read_lock();
retval = max_select_fd(n, fds);
rcu_read_unlock();
n = retval;
poll_initwait(&table); //初始化等待队列
wait = &table.pt;
if (end_time && !end_time->tv_sec && !end_time->tv_nsec) {
wait->_qproc = NULL;
timed_out = 1;
}
if (end_time && !timed_out)
slack = select_estimate_accuracy(end_time);
retval = 0;
for (;;) {
unsigned long *rinp, *routp, *rexp, *inp, *outp, *exp;
bool can_busy_loop = false;
inp = fds->in; outp = fds->out; exp = fds->ex;
rinp = fds->res_in; routp = fds->res_out; rexp = fds->res_ex;
// 触目惊心的双层循环,外面的哪一层可以不用太过纠结
for (i = 0; i < n; ++rinp, ++routp, ++rexp) {
unsigned long in, out, ex, all_bits, bit = 1, mask, j;
unsigned long res_in = 0, res_out = 0, res_ex = 0;
in = *inp++; out = *outp++; ex = *exp++;
all_bits = in | out | ex;
if (all_bits == 0) {
i += BITS_PER_LONG; //以32bits步长遍历位图,直到在该区间存在目标fd
continue;
}
for (j = 0; j < BITS_PER_LONG; ++j, ++i, bit <<= 1) {
struct fd f;
if (i >= n)
break;
if (!(bit & all_bits))
continue;
f = fdget(i); //找到目标fd
if (f.file) {
const struct file_operations *f_op;
f_op = f.file->f_op;
mask = DEFAULT_POLLMASK;
if (f_op->poll) {
wait_key_set(wait, in, out, bit, busy_flag);
//执行文件系统的poll函数,检测IO事件
mask = (*f_op->poll)(f.file, wait);
}
fdput(f);
//写入in/out/ex相对应的结果
if ((mask & POLLIN_SET) && (in & bit)) {
res_in |= bit;
retval++;
wait->_qproc = NULL;
}
if ((mask & POLLOUT_SET) && (out & bit)) {
res_out |= bit;
retval++;
wait->_qproc = NULL;
}
if ((mask & POLLEX_SET) && (ex & bit)) {
res_ex |= bit;
retval++;
wait->_qproc = NULL;
}
//当返回值不为零,则停止循环轮询
if (retval) {
can_busy_loop = false;
busy_flag = 0;
} else if (busy_flag & mask)
can_busy_loop = true;
}
}
//本轮循环遍历完成,则更新fd事件的结果
if (res_in)
*rinp = res_in;
if (res_out)
*routp = res_out;
if (res_ex)
*rexp = res_ex;
cond_resched(); //让出cpu给其他进程运行,类似于上层的yield
}
wait->_qproc = NULL;
//当有文件描述符准备就绪 或者超时 或者 有待处理的信号,则退出循环
if (retval || timed_out || signal_pending(current))
break;
if (table.error) {
retval = table.error;
break;
}
if (can_busy_loop && !need_resched()) {
if (!busy_end) {
busy_end = busy_loop_end_time();
continue;
}
if (!busy_loop_timeout(busy_end))
continue;
}
busy_flag = 0;
if (end_time && !to) { //首轮循环设置超时
expire = timespec_to_ktime(*end_time);
to = &expire;
}
//设置当前进程状态为TASK_INTERRUPTIBLE,进入睡眠直到超时
if (!poll_schedule_timeout(&table, TASK_INTERRUPTIBLE,
to, slack))
timed_out = 1;
}
poll_freewait(&table); //释放poll等待队列
return retval;
}
do_select()是整个select的核心过程,主要工作流程如下:
- 当存在被监控的fd触发目标事件,则将其fd记录下来,退出循环体,返回用户空间;
- 当没有找到目标事件,如果已超时或者有待处理的信号,也会退出循环体,返回空给用户空间;
- 当以上两种情况都不满足,则会让当前进程进入休眠状态,以等待fd或者超时定时器来唤醒自己,再走一遍循环。
具体关联实现:
- poll_initwait():设置poll_wqueues->poll_table的成员变量poll_queue_proc为__pollwait函数;同时记录当前进程task_struct记在pwq结构体的polling_task。
- f_op->poll():会调用poll_wait(),进而执行上一步设置的方法__pollwait();
- __pollwait():设置wait->func唤醒回调函数为pollwake函数,并将poll_table_entry->wait加入等待队列
- poll_schedule_timeout():该进程进入带有超时的睡眠状态。
- 之后,当其他进程就绪事件发生时便会唤醒相应等待队列上的进程。比如监控的是可写事件,则会在write()方法中调用wake_up方法唤醒相对应的等待队列上的进程,当唤醒后执行前面设置的唤醒回调函数pollwake函数。
- pollwake():先从wait->private的polling_task获取处于等待睡眠状态的目标进程,调用* default_wake_function()来唤醒该进程;
- poll_freewait():当进程唤醒后,将就绪事件结果保存在fds的res_in、res_out、res_ex,然后把该等待队列从该队列头中移除。
- 回到core_sys_select(),将就绪事件结果拷贝到用户空间。
这里有一个缺陷大家其实也都清楚了,就是每次会轮询所有的fd的f_op->poll(),这也就是select和poll在同时监听文件过多时,性能会下降严重的原因。
poll 源码学习
static int do_poll(unsigned int nfds, struct poll_list *list,
struct poll_wqueues *wait, struct timespec *end_time)
{
poll_table* pt = &wait->pt;
ktime_t expire, *to = NULL;
int timed_out = 0, count = 0;
u64 slack = 0;
unsigned int busy_flag = net_busy_loop_on() ? POLL_BUSY_LOOP : 0;
unsigned long busy_end = 0;
// 优化非阻塞的情形
if (end_time && !end_time->tv_sec && !end_time->tv_nsec) {
pt->_qproc = NULL;
timed_out = 1;
}
if (end_time && !timed_out)
slack = select_estimate_accuracy(end_time);
for (;;) {
struct poll_list *walk;
bool can_busy_loop = false;
for (walk = list; walk != NULL; walk = walk->next) {
struct pollfd * pfd, * pfd_end;
pfd = walk->entries;
pfd_end = pfd + walk->len;
for (; pfd != pfd_end; pfd++) {
//源码见下方
if (do_pollfd(pfd, pt, &can_busy_loop,
busy_flag)) {
count++;
pt->_qproc = NULL;
busy_flag = 0; //找到目标事件,可跳出循环
can_busy_loop = false;
}
}
}
//所有的waiters已注册,因此不需要为下一轮循环提供poll_table->_qproc
pt->_qproc = NULL;
if (!count) {
count = wait->error;
if (signal_pending(current)) //有待处理信号,则跳出循环
count = -EINTR;
}
if (count || timed_out) //监控事件触发,或者超时则跳出循环
break;
if (can_busy_loop && !need_resched()) {
if (!busy_end) {
busy_end = busy_loop_end_time();
continue;
}
if (!busy_loop_timeout(busy_end))
continue;
}
busy_flag = 0;
if (end_time && !to) { //首轮循环设置超时
expire = timespec_to_ktime(*end_time);
to = &expire;
}
//设置当前进程状态为TASK_INTERRUPTIBLE,进入睡眠直到超时
if (!poll_schedule_timeout(wait, TASK_INTERRUPTIBLE, to, slack))
timed_out = 1;
}
return count;
}
...
static inline unsigned int do_pollfd(struct pollfd *pollfd,
poll_table *pwait,
bool *can_busy_poll,
unsigned int busy_flag)
{
unsigned int mask;
int fd;
mask = 0;
fd = pollfd->fd;
if (fd >= 0) {
struct fd f = fdget(fd);
mask = POLLNVAL;
if (f.file) {
mask = DEFAULT_POLLMASK;
if (f.file->f_op->poll) {
pwait->_key = pollfd->events|POLLERR|POLLHUP;
pwait->_key |= busy_flag;
//同上【2.4.2】
mask = f.file->f_op->poll(f.file, pwait);
if (mask & busy_flag)
*can_busy_poll = true;
}
mask &= pollfd->events | POLLERR | POLLHUP;
fdput(f);
}
}
pollfd->revents = mask;
return mask;
}
Linux驱动程序提供休眠/唤醒机制:
- 等待队列select:当事件满足要求,则唤醒所有的等待队列项。一个进程可以等待多个不同等待队列,以及指定相应的唤醒时回调函数。一般来说,等待状态的进程处于睡眠,回调函数则相应会唤醒进程。
- 轮询函数poll:执行指定的回调函数,将驱动的等待队列给外部代码。
我们发现,select和poll机制的原理非常相近,主要是一些数据结构的不同,最终到驱动层都会执行f_op->poll(),执行__pollwait()把自己挂入等待队列。 一旦有事件发生时便会唤醒等待队列上的进程。比如监控的是可写事件,则会在write()方法中调用wakeup方法唤醒相对应的等待队列上的进程。这一切都是基于底层文件系统作为基石来完成IO多路复用的事件监控功能。
epoll源码学习
看过了select和poll的,我们再来看epoll的,上面的代码,可能最介意的就是一次次的循环遍历文件列表了吧,那我们来看看epoll是怎么干掉这层循环的
前置了解
epoll最主要的三个函数:
// 调用epoll_create建立一个epoll对象(在epoll文件系统中给这个句柄分配资源);
int epoll_create(int size);
// 调用epoll_ctl向epoll对象中添加这100万个连接的套接字;
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
// 调用epoll_wait收集发生事件的连接。
int epoll_wait(int epfd, struct epoll_event *events,int maxevents, int timeout);
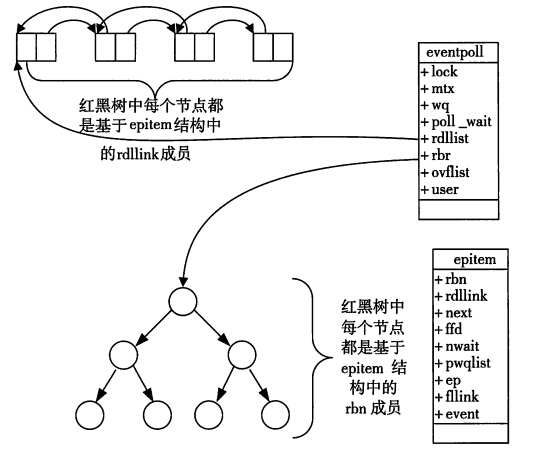
我们在调用epoll_create时,内核除了帮我们在epoll文件系统里建了个file结点,在内核cache里建了个红黑树用于存储以后epoll_ctl传来的socket外,还会再建立一个rdllist双向链表,用于存储准备就绪的事件,当epoll_wait调用时,仅仅观察这个rdllist双向链表里有没有数据即可。有数据就返回,没有数据就sleep,等到timeout时间到后即使链表没数据也返回。所以,epoll_wait非常高效。
最主要的两个结构体:
// 调用epoll_create方法时,Linux内核会创建一个eventpoll结构体,这个结构体中有两个成员与epoll的使用方式密切相关
struct eventpoll {
...
/*红黑树的根节点,这棵树中存储着所有添加到epoll中的事件,
也就是这个epoll监控的事件*/
struct rb_root rbr;
/*双向链表rdllist保存着将要通过epoll_wait返回给用户的、满足条件的事件*/
struct list_head rdllist;
...
};
...
// 在epoll中对于每一个事件都会建立一个epitem结构体
struct epitem {
...
//红黑树节点
struct rb_node rbn;
//双向链表节点
struct list_head rdllink;
//事件句柄等信息
struct epoll_filefd ffd;
//指向其所属的eventepoll对象
struct eventpoll *ep;
//期待的事件类型
struct epoll_event event;
...
}; // 这里包含每一个事件对应着的信息。
当调用epoll_wait检查是否有发生事件的连接时,只是检查eventpoll对象中的rdllist双向链表是否有epitem元素而已,如果rdllist链表不为空,则这里的事件复制到用户态内存(使用共享内存提高效率)中,同时将事件数量返回给用户。因此epoll_wait效率非常高。epoll_ctl在向epoll对象中添加、修改、删除事件时,从rbr红黑树中查找事件也非常快,也就是说epoll是非常高效的,它可以轻易地处理百万级别的并发连接
epoll_create 函数
- 从slab缓存中创建一个eventpoll对象,并且创建一个匿名的fd跟fd对应的file对象,而eventpoll对象保存在struct file结构的private指针中,并且返回,
- 该fd对应的file operations只是实现了poll跟release操作,创建eventpoll对象的初始化操作
获取当前用户信息,是不是root,最大监听fd数目等并且保存到eventpoll对象中 - 初始化等待队列,初始化就绪链表,初始化红黑树的头结点
//先进行判断size是否>=0,若是则直接调用epoll_create1
// SYSCALL_DEFINE1是一个宏,用于定义有一个参数的系统调用函数,上述宏展开后即成为: int sys_epoll_create(int size),这就是epoll_create系统调用的入口。至于为何要用宏而不是直接声明,主要是因为系统调用的参数个数、传参方式都有严格限制,最多六个参数
SYSCALL_DEFINE1(epoll_create, int, size)
{
if (size <= 0)
return -EINVAL;
return sys_epoll_create1(0);
}
/* 这才是真正的epoll_create啊~~ */
SYSCALL_DEFINE1(epoll_create1, int, flags)
{
int error;
struct eventpoll *ep = NULL;//主描述符
/* Check the EPOLL_* constant for consistency. */
/* 这句没啥用处... */
BUILD_BUG_ON(EPOLL_CLOEXEC != O_CLOEXEC);
/* 对于epoll来讲, 目前唯一有效的FLAG就是CLOEXEC */
if (flags & ~EPOLL_CLOEXEC)
return -EINVAL;
/*
* Create the internal data structure ("struct eventpoll").
*/
/* 分配一个struct eventpoll, 分配和初始化细节我们随后深聊~ */
error = ep_alloc(&ep);
if (error < 0)
return error;
/*
* Creates all the items needed to setup an eventpoll file. That is,
* a file structure and a free file descriptor.
*/
/* 这里是创建一个匿名fd, 说起来就话长了...长话短说:
* epollfd本身并不存在一个真正的文件与之对应, 所以内核需要创建一个
* "虚拟"的文件, 并为之分配真正的struct file结构, 而且有真正的fd.
* 这里2个参数比较关键:
* eventpoll_fops, fops就是file operations, 就是当你对这个文件(这里是虚拟的)进行操作(比如读)时,
* fops里面的函数指针指向真正的操作实现, 类似C++里面虚函数和子类的概念.
* epoll只实现了poll和release(就是close)操作, 其它文件系统操作都有VFS全权处理了.
* ep, ep就是struct epollevent, 它会作为一个私有数据保存在struct file的private指针里面.
* 其实说白了, 就是为了能通过fd找到struct file, 通过struct file能找到eventpoll结构.
* 如果懂一点Linux下字符设备驱动开发, 这里应该是很好理解的,
* 推荐阅读 <Linux device driver 3rd>
*/
error = anon_inode_getfd("[eventpoll]", &eventpoll_fops, ep,
O_RDWR | (flags & O_CLOEXEC));
if (error < 0)
ep_free(ep);
return error;
}
// epoll 文件系统的相关实现
// epoll 文件系统初始化, 在系统启动时会调用
static int __init eventpoll_init(void)
{
struct sysinfo si;
si_meminfo(&si);
// 限制可添加到epoll的最多的描述符数量
max_user_watches = (((si.totalram - si.totalhigh) / 25) << PAGE_SHIFT) /
EP_ITEM_COST;
BUG_ON(max_user_watches < 0);
// 初始化递归检查队列
ep_nested_calls_init(&poll_loop_ncalls);
ep_nested_calls_init(&poll_safewake_ncalls);
ep_nested_calls_init(&poll_readywalk_ncalls);
// epoll 使用的slab分配器分别用来分配epitem和eppoll_entry
epi_cache = kmem_cache_create("eventpoll_epi", sizeof(struct epitem),
0, SLAB_HWCACHE_ALIGN | SLAB_PANIC, NULL);
pwq_cache = kmem_cache_create("eventpoll_pwq",
sizeof(struct eppoll_entry), 0, SLAB_PANIC, NULL);
return 0;
}
epoll_ctl 函数
- 将epoll_event结构拷贝到内核空间中,并且判断加入的fd是否支持poll结(epoll,poll,selectI/O多路复用必须支持poll操作).
- 从epfd->file->privatedata获取event_poll对象,根据op区分是添加删除还是修改,
- 首先在eventpoll结构中的红黑树查找是否已经存在了相对应的fd,没找到就支持插入操作,否则报重复的错误,还有修改,删除操作。
- 插入操作时,会创建一个与fd对应的epitem结构,并且初始化相关成员,并指定调用poll_wait时的回调函数用于数据就绪时唤醒进程,(其内部,初始化设备的等待队列,将该进程注册到等待队列)完成这一步
- epitem就跟这个socket关联起来了, 当它有状态变化时,会通过ep_poll_callback()来通知.
- 最后调用加入的fd的fileoperation->poll函数(最后会调用poll_wait操作)用于完注册操作,将epitem结构添加到红黑树中。
//创建好epollfd后, 接下来添加fd
//epoll_ctl的参数:epfd 表示epollfd;op 有ADD,MOD,DEL,
//fd 是需要监听的描述符,event 我们感兴趣的events
SYSCALL_DEFINE4(epoll_ctl, int, epfd, int, op, int, fd,
struct epoll_event __user *, event)
{
int error;
int did_lock_epmutex = 0;
struct file *file, *tfile;
struct eventpoll *ep;
struct epitem *epi;
struct epoll_event epds;
error = -EFAULT;
//错误处理以及从用户空间将epoll_event结构copy到内核空间.
if (ep_op_has_event(op) &&
// 复制用户空间数据到内核
copy_from_user(&epds, event, sizeof(struct epoll_event))) {
goto error_return;
}
// 取得 epfd 对应的文件
error = -EBADF;
file = fget(epfd);
if (!file) {
goto error_return;
}
// 取得目标文件
tfile = fget(fd);
if (!tfile) {
goto error_fput;
}
// 目标文件必须提供 poll 操作
error = -EPERM;
if (!tfile->f_op || !tfile->f_op->poll) {
goto error_tgt_fput;
}
// 添加自身或epfd 不是epoll 句柄
error = -EINVAL;
if (file == tfile || !is_file_epoll(file)) {
goto error_tgt_fput;
}
// 取得内部结构eventpoll
ep = file->private_data;
// EPOLL_CTL_MOD 不需要加全局锁 epmutex
if (op == EPOLL_CTL_ADD || op == EPOLL_CTL_DEL) {
mutex_lock(&epmutex);
did_lock_epmutex = 1;
}
if (op == EPOLL_CTL_ADD) {
if (is_file_epoll(tfile)) {
error = -ELOOP;
// 目标文件也是epoll 检测是否有循环包含的问题
if (ep_loop_check(ep, tfile) != 0) {
goto error_tgt_fput;
}
} else
{
// 将目标文件添加到 epoll 全局的tfile_check_list 中
list_add(&tfile->f_tfile_llink, &tfile_check_list);
}
}
mutex_lock_nested(&ep->mtx, 0);
// 以tfile 和fd 为key 在rbtree 中查找文件对应的epitem
epi = ep_find(ep, tfile, fd);
error = -EINVAL;
switch (op) {
case EPOLL_CTL_ADD:
if (!epi) {
// 没找到, 添加额外添加ERR HUP 事件
epds.events |= POLLERR | POLLHUP;
error = ep_insert(ep, &epds, tfile, fd);
} else {
error = -EEXIST;
}
// 清空文件检查列表
clear_tfile_check_list();
break;
case EPOLL_CTL_DEL:
if (epi) {
error = ep_remove(ep, epi);
} else {
error = -ENOENT;
}
break;
case EPOLL_CTL_MOD:
if (epi) {
epds.events |= POLLERR | POLLHUP;
error = ep_modify(ep, epi, &epds);
} else {
error = -ENOENT;
}
break;
}
mutex_unlock(&ep->mtx);
error_tgt_fput:
if (did_lock_epmutex) {
mutex_unlock(&epmutex);
}
fput(tfile);
error_fput:
fput(file);
error_return:
return error;
}
//ep_insert()在epoll_ctl()中被调用, 完成往epollfd里面添加一个监听fd的工作
static int ep_insert(struct eventpoll *ep, struct epoll_event *event,
struct file *tfile, int fd)
{
int error, revents, pwake = 0;
unsigned long flags;
long user_watches;
struct epitem *epi;
struct ep_pqueue epq;
/*
struct ep_pqueue {
poll_table pt;
struct epitem *epi;
};
*/
// 增加监视文件数
user_watches = atomic_long_read(&ep->user->epoll_watches);
if (unlikely(user_watches >= max_user_watches)) {
return -ENOSPC;
}
// 分配初始化 epi
if (!(epi = kmem_cache_alloc(epi_cache, GFP_KERNEL))) {
return -ENOMEM;
}
INIT_LIST_HEAD(&epi->rdllink);
INIT_LIST_HEAD(&epi->fllink);
INIT_LIST_HEAD(&epi->pwqlist);
epi->ep = ep;
// 初始化红黑树中的key
ep_set_ffd(&epi->ffd, tfile, fd);
// 直接复制用户结构
epi->event = *event;
epi->nwait = 0;
epi->next = EP_UNACTIVE_PTR;
// 初始化临时的 epq
epq.epi = epi;
init_poll_funcptr(&epq.pt, ep_ptable_queue_proc);
// 设置事件掩码
epq.pt._key = event->events;
// 内部会调用ep_ptable_queue_proc, 在文件对应的wait queue head 上
// 注册回调函数, 并返回当前文件的状态
revents = tfile->f_op->poll(tfile, &epq.pt);
// 检查错误
error = -ENOMEM;
if (epi->nwait < 0) { // f_op->poll 过程出错
goto error_unregister;
}
// 添加当前的epitem 到文件的f_ep_links 链表
spin_lock(&tfile->f_lock);
list_add_tail(&epi->fllink, &tfile->f_ep_links);
spin_unlock(&tfile->f_lock);
// 插入epi 到rbtree
ep_rbtree_insert(ep, epi);
/* now check if we've created too many backpaths */
error = -EINVAL;
if (reverse_path_check()) {
goto error_remove_epi;
}
spin_lock_irqsave(&ep->lock, flags);
/* 文件已经就绪插入到就绪链表rdllist */
if ((revents & event->events) && !ep_is_linked(&epi->rdllink)) {
list_add_tail(&epi->rdllink, &ep->rdllist);
if (waitqueue_active(&ep->wq))
// 通知sys_epoll_wait , 调用回调函数唤醒sys_epoll_wait 进程
{
wake_up_locked(&ep->wq);
}
// 先不通知调用eventpoll_poll 的进程
if (waitqueue_active(&ep->poll_wait)) {
pwake++;
}
}
spin_unlock_irqrestore(&ep->lock, flags);
atomic_long_inc(&ep->user->epoll_watches);
if (pwake)
// 安全通知调用eventpoll_poll 的进程
{
ep_poll_safewake(&ep->poll_wait);
}
return 0;
error_remove_epi:
spin_lock(&tfile->f_lock);
// 删除文件上的 epi
if (ep_is_linked(&epi->fllink)) {
list_del_init(&epi->fllink);
}
spin_unlock(&tfile->f_lock);
// 从红黑树中删除
rb_erase(&epi->rbn, &ep->rbr);
error_unregister:
// 从文件的wait_queue 中删除, 释放epitem 关联的所有eppoll_entry
ep_unregister_pollwait(ep, epi);
spin_lock_irqsave(&ep->lock, flags);
if (ep_is_linked(&epi->rdllink)) {
list_del_init(&epi->rdllink);
}
spin_unlock_irqrestore(&ep->lock, flags);
// 释放epi
kmem_cache_free(epi_cache, epi);
return error;
}
static unsigned int ep_eventpoll_poll(struct file *file, poll_table *wait)
{
int pollflags;
struct eventpoll *ep = file->private_data;
// 插入到wait_queue
poll_wait(file, &ep->poll_wait, wait);
// 扫描就绪的文件列表, 调用每个文件上的poll 检测是否真的就绪,
// 然后复制到用户空间
// 文件列表中有可能有epoll文件, 调用poll的时候有可能会产生递归,
// 调用所以用ep_call_nested 包装一下, 防止死循环和过深的调用
pollflags = ep_call_nested(&poll_readywalk_ncalls, EP_MAX_NESTS,
ep_poll_readyevents_proc, ep, ep, current);
// static struct nested_calls poll_readywalk_ncalls;
return pollflags != -1 ? pollflags : 0;
}
// 通用的poll_wait 函数, 文件的f_ops->poll 通常会调用此函数
static inline void poll_wait(struct file * filp, wait_queue_head_t * wait_address, poll_table *p)
{
if (p && p->_qproc && wait_address) {
// 调用_qproc 在wait_address 上添加节点和回调函数
// 调用 poll_table_struct 上的函数指针向wait_address添加节点, 并设置节点的func
// (如果是select或poll 则是 __pollwait, 如果是 epoll 则是 ep_ptable_queue_proc),
p->_qproc(filp, wait_address, p);
}
}
/*
* 该函数在调用f_op->poll()时会被调用.
* 也就是epoll主动poll某个fd时, 用来将epitem与指定的fd关联起来的.
* 关联的办法就是使用等待队列(waitqueue)
*/
static void ep_ptable_queue_proc(struct file *file, wait_queue_head_t *whead,
poll_table *pt)
{
struct epitem *epi = ep_item_from_epqueue(pt);
struct eppoll_entry *pwq;
if (epi->nwait >= 0 && (pwq = kmem_cache_alloc(pwq_cache, GFP_KERNEL))) {
/* 初始化等待队列, 指定ep_poll_callback为唤醒时的回调函数,
* 当我们监听的fd发生状态改变时, 也就是队列头被唤醒时,
* 指定的回调函数将会被调用. */
init_waitqueue_func_entry(&pwq->wait, ep_poll_callback);
pwq->whead = whead;
pwq->base = epi;
/* 将刚分配的等待队列成员加入到头中, 头是由fd持有的 */
add_wait_queue(whead, &pwq->wait);
list_add_tail(&pwq->llink, &epi->pwqlist);
/* nwait记录了当前epitem加入到了多少个等待队列中,
* 我认为这个值最大也只会是1... */
epi->nwait++;
} else {
/* We have to signal that an error occurred */
epi->nwait = -1;
}
}
//回调函数, 当我们监听的fd发生状态改变时, 它会被调用.
static int ep_poll_callback(wait_queue_t *wait, unsigned mode, int sync, void *key)
{
int pwake = 0;
unsigned long flags;
//从等待队列获取epitem.需要知道哪个进程挂载到这个设备
struct epitem *epi = ep_item_from_wait(wait);
struct eventpoll *ep = epi->ep;//获取
spin_lock_irqsave(&ep->lock, flags);
if (!(epi->event.events & ~EP_PRIVATE_BITS))
goto out_unlock;
/* 没有我们关心的event... */
if (key && !((unsigned long) key & epi->event.events))
goto out_unlock;
/*
* 这里看起来可能有点费解, 其实干的事情比较简单:
* 如果该callback被调用的同时, epoll_wait()已经返回了,
* 也就是说, 此刻应用程序有可能已经在循环获取events,
* 这种情况下, 内核将此刻发生event的epitem用一个单独的链表
* 链起来, 不发给应用程序, 也不丢弃, 而是在下一次epoll_wait
* 时返回给用户.
*/
if (unlikely(ep->ovflist != EP_UNACTIVE_PTR)) {
if (epi->next == EP_UNACTIVE_PTR) {
epi->next = ep->ovflist;
ep->ovflist = epi;
}
goto out_unlock;
}
/* 将当前的epitem放入ready list */
if (!ep_is_linked(&epi->rdllink))
list_add_tail(&epi->rdllink, &ep->rdllist);
/* 唤醒epoll_wait... */
if (waitqueue_active(&ep->wq))
wake_up_locked(&ep->wq);
/* 如果epollfd也在被poll, 那就唤醒队列里面的所有成员. */
if (waitqueue_active(&ep->poll_wait))
pwake++;
out_unlock:
spin_unlock_irqrestore(&ep->lock, flags);
/* We have to call this outside the lock */
if (pwake)
ep_poll_safewake(&ep->poll_wait);
return 1;
}
static int ep_remove(struct eventpoll *ep, struct epitem *epi)
{
unsigned long flags;
struct file *file = epi->ffd.file;
/*
* Removes poll wait queue hooks. We _have_ to do this without holding
* the "ep->lock" otherwise a deadlock might occur. This because of the
* sequence of the lock acquisition. Here we do "ep->lock" then the wait
* queue head lock when unregistering the wait queue. The wakeup callback
* will run by holding the wait queue head lock and will call our callback
* that will try to get "ep->lock".
*/
ep_unregister_pollwait(ep, epi);
/* Remove the current item from the list of epoll hooks */
spin_lock(&file->f_lock);
if (ep_is_linked(&epi->fllink))
list_del_init(&epi->fllink);
spin_unlock(&file->f_lock);
rb_erase(&epi->rbn, &ep->rbr);
spin_lock_irqsave(&ep->lock, flags);
if (ep_is_linked(&epi->rdllink))
list_del_init(&epi->rdllink);
spin_unlock_irqrestore(&ep->lock, flags);
/* At this point it is safe to free the eventpoll item */
kmem_cache_free(epi_cache, epi);
atomic_long_dec(&ep->user->epoll_watches);
return 0;
}
static int ep_modify(struct eventpoll *ep, struct epitem *epi, struct epoll_event *event)
{
int pwake = 0;
unsigned int revents;
poll_table pt;
init_poll_funcptr(&pt, NULL);
/*
* Set the new event interest mask before calling f_op->poll();
* otherwise we might miss an event that happens between the
* f_op->poll() call and the new event set registering.
*/
epi->event.events = event->events;
pt._key = event->events;
epi->event.data = event->data; /* protected by mtx */
/*
* Get current event bits. We can safely use the file* here because
* its usage count has been increased by the caller of this function.
*/
revents = epi->ffd.file->f_op->poll(epi->ffd.file, &pt);
/*
* If the item is "hot" and it is not registered inside the ready
* list, push it inside.
*/
if (revents & event->events) {
spin_lock_irq(&ep->lock);
if (!ep_is_linked(&epi->rdllink)) {
list_add_tail(&epi->rdllink, &ep->rdllist);
/* Notify waiting tasks that events are available */
if (waitqueue_active(&ep->wq))
wake_up_locked(&ep->wq);
if (waitqueue_active(&ep->poll_wait))
pwake++;
}
spin_unlock_irq(&ep->lock);
}
/* We have to call this outside the lock */
if (pwake)
ep_poll_safewake(&ep->poll_wait);
return 0;
}
epoll_wait 函数
- 计算睡眠时间(如果有),判断eventpoll对象的链表是否为空,不为空那就干活不睡明.并且初始化一个等待队列,把自己挂上去,设置自己的进程状态
- 若是可睡眠状态.判断是否有信号到来(有的话直接被中断醒来,),如果没有那就调用schedule_timeout进行睡眠,
- 如果超时或者被唤醒,首先从自己初始化的等待队列删除,然后开始拷贝资源给用户空间了
- 拷贝资源则是先把就绪事件链表转移到中间链表,然后挨个遍历拷贝到用户空间,并且挨个判断其是否为水平触发,是的话再次插入到就绪链表
SYSCALL_DEFINE4(epoll_wait, int, epfd, struct epoll_event __user *, events,
int, maxevents, int, timeout)
{
int error;
struct file *file;
struct eventpoll *ep;
/* The maximum number of event must be greater than zero */
if (maxevents <= 0 || maxevents > EP_MAX_EVENTS)
return -EINVAL;
/* Verify that the area passed by the user is writeable */
/* 这个地方有必要说明一下:
* 内核对应用程序采取的策略是"绝对不信任",
* 所以内核跟应用程序之间的数据交互大都是copy, 不允许(也时候也是不能...)指针引用.
* epoll_wait()需要内核返回数据给用户空间, 内存由用户程序提供,
* 所以内核会用一些手段来验证这一段内存空间是不是有效的.
*/
if (!access_ok(VERIFY_WRITE, events, maxevents * sizeof(struct epoll_event))) {
error = -EFAULT;
goto error_return;
}
/* Get the "struct file *" for the eventpoll file */
error = -EBADF;
/* 获取epollfd的struct file, epollfd也是文件嘛 */
file = fget(epfd);
if (!file)
goto error_return;
error = -EINVAL;
/* 检查一下它是不是一个真正的epollfd... */
if (!is_file_epoll(file))
goto error_fput;
/* 获取eventpoll结构 */
ep = file->private_data;
/* 等待事件到来~~ */
error = ep_poll(ep, events, maxevents, timeout);
error_fput:
fput(file);
error_return:
return error;
}
/* 这个函数真正将执行epoll_wait的进程带入睡眠状态... */
static int ep_poll(struct eventpoll *ep, struct epoll_event __user *events,
int maxevents, long timeout)
{
int res, eavail;
unsigned long flags;
long jtimeout;
wait_queue_t wait;//等待队列
/* 计算睡觉时间, 毫秒要转换为HZ */
jtimeout = (timeout < 0 || timeout >= EP_MAX_MSTIMEO) ?
MAX_SCHEDULE_TIMEOUT : (timeout * HZ + 999) / 1000;
retry:
spin_lock_irqsave(&ep->lock, flags);
res = 0;
/* 如果ready list不为空, 就不睡了, 直接干活... */
if (list_empty(&ep->rdllist)) {
/* OK, 初始化一个等待队列, 准备直接把自己挂起,
* 注意current是一个宏, 代表当前进程 */
init_waitqueue_entry(&wait, current);//初始化等待队列,wait表示当前进程
__add_wait_queue_exclusive(&ep->wq, &wait);//挂载到ep结构的等待队列
for (;;) {
/* 将当前进程设置位睡眠, 但是可以被信号唤醒的状态,
* 注意这个设置是"将来时", 我们此刻还没睡! */
set_current_state(TASK_INTERRUPTIBLE);
/* 如果这个时候, ready list里面有成员了,
* 或者睡眠时间已经过了, 就直接不睡了... */
if (!list_empty(&ep->rdllist) || !jtimeout)
break;
/* 如果有信号产生, 也起床... */
if (signal_pending(current)) {
res = -EINTR;
break;
}
/* 啥事都没有,解锁, 睡觉... */
spin_unlock_irqrestore(&ep->lock, flags);
/* jtimeout这个时间后, 会被唤醒,
* ep_poll_callback()如果此时被调用,
* 那么我们就会直接被唤醒, 不用等时间了...
* 再次强调一下ep_poll_callback()的调用时机是由被监听的fd
* 的具体实现, 比如socket或者某个设备驱动来决定的,
* 因为等待队列头是他们持有的, epoll和当前进程
* 只是单纯的等待...
**/
jtimeout = schedule_timeout(jtimeout);//睡觉
spin_lock_irqsave(&ep->lock, flags);
}
__remove_wait_queue(&ep->wq, &wait);
/* OK 我们醒来了... */
set_current_state(TASK_RUNNING);
}
/* Is it worth to try to dig for events ? */
eavail = !list_empty(&ep->rdllist) || ep->ovflist != EP_UNACTIVE_PTR;
spin_unlock_irqrestore(&ep->lock, flags);
/* 如果一切正常, 有event发生, 就开始准备数据copy给用户空间了... */
if (!res && eavail &&
!(res = ep_send_events(ep, events, maxevents)) && jtimeout)
goto retry;
return res;
}
//调用p_scan_ready_list()
static int ep_send_events(struct eventpoll *ep,
struct epoll_event __user *events, int maxevents)
{
struct ep_send_events_data esed;
esed.maxevents = maxevents;
esed.events = events;
return ep_scan_ready_list(ep, ep_send_events_proc, &esed);
}
//由ep_send_events()调用本函数
static int ep_scan_ready_list(struct eventpoll *ep,
int (*sproc)(struct eventpoll *,
struct list_head *, void *),
void *priv)
{
int error, pwake = 0;
unsigned long flags;
struct epitem *epi, *nepi;
LIST_HEAD(txlist);
mutex_lock(&ep->mtx);
spin_lock_irqsave(&ep->lock, flags);
/* 这一步要注意, 首先, 所有监听到events的epitem都链到rdllist上了,
* 但是这一步之后, 所有的epitem都转移到了txlist上, 而rdllist被清空了,
* 要注意哦, rdllist已经被清空了! */
list_splice_init(&ep->rdllist, &txlist);
/* ovflist, 在ep_poll_callback()里面我解释过, 此时此刻我们不希望
* 有新的event加入到ready list中了, 保存后下次再处理... */
ep->ovflist = NULL;
spin_unlock_irqrestore(&ep->lock, flags);
/* 在这个回调函数里面处理每个epitem
* sproc 就是 ep_send_events_proc, 下面会注释到. */
error = (*sproc)(ep, &txlist, priv);
spin_lock_irqsave(&ep->lock, flags);
/* 现在我们来处理ovflist, 这些epitem都是我们在传递数据给用户空间时
* 监听到了事件. */
for (nepi = ep->ovflist; (epi = nepi) != NULL;
nepi = epi->next, epi->next = EP_UNACTIVE_PTR) {
/* 将这些直接放入readylist */
if (!ep_is_linked(&epi->rdllink))
list_add_tail(&epi->rdllink, &ep->rdllist);
}
ep->ovflist = EP_UNACTIVE_PTR;
/* 上一次没有处理完的epitem, 重新插入到ready list */
list_splice(&txlist, &ep->rdllist);
/* ready list不为空, 直接唤醒... */
if (!list_empty(&ep->rdllist)) {
if (waitqueue_active(&ep->wq))
wake_up_locked(&ep->wq);
if (waitqueue_active(&ep->poll_wait))
pwake++;
}
spin_unlock_irqrestore(&ep->lock, flags);
mutex_unlock(&ep->mtx);
/* We have to call this outside the lock */
if (pwake)
ep_poll_safewake(&ep->poll_wait);
return error;
}
总结
可以看到,epoll的代码最关键的地方就在于回调函数的使用,加上结构体的设计,实现了对于poll和select中承载能力受限、效率随着处理文件数而降低的一大难题。
看这些代码的时候,很多见到过的套路和方法原来在这里也有应用,有种技术的底层果然相通的感觉。
而此时也终于明白了为什么红黑树会如此重要,期待之后专门开篇学习下红黑树吧。
附上网上讨来的一份调用链路,侵删。
引用
来了解一下线程的前世今生
也来谈谈协程
线程和IO模型的极简知识
Linux IO模式及 select、poll、epoll详解
linux epoll详解及使用方法概述
epoll详解——从功能到内核
epoll原理详解及epoll反应堆模型
源码解读poll/select内核机制
Epoll的本质(内部实现原理)
内核IO模型介绍
【Linux深入】epoll源码剖析